人脸检测方案BlazeFace解读
来自Google的轻量级人脸检测方案

BlazeFace是Google专为移动端GPU定制的人脸检测方案。作者将其贡献概括为:
- 专为轻量级检测定制的紧凑型特征提取网络,类MobielNet。
- 相比SSD模型,对GPU更友好的anchor机制。
- 采用“tie resolution strategy”而非NMS处理重叠的预测结果。
BlazeFace除了提供面部边界框外,还可以输出6个特征点的坐标:双眼中央、耳垂、嘴部中央与鼻尖。

作者认为在模型方面BlazeFace的创新可以概括为四个重点如下。
BlazeBlock
Seprable convolution是轻量网络经常采用的卷积形式。它使用两步卷积运算Depthwise卷积与Pointwise卷积替代常规的单次卷积。作者在iPhone上实测后发现,一个56×56×128大小、16-bit张量的Depthwise卷积运算耗时0.07ms,而伴随其后128-128通道的Pointwise卷积运算耗时0.3ms,是前者的4倍以上(作者认为是内存存取的固定开销造成)。因此作者提出在Depthwise卷积中使用较大的卷积核,这样只需要较少的bottleneck数量就可以获得指定大小的感受野范围。作者将该结构命名为 BlazeBlock。
如果你对Separable convolution不熟悉的话,我之前写过一篇文章解释过其原理:
 Yin Guobing
Yin Guobing
MobielNet v2的状况则稍微复杂一些。作者将bottlenek的“扩张-收缩”策略反转,变成“收缩-扩张”。作者解释说这么做的原因是为了“补偿内部张量之间稀少的通道数”(我个人表示怀疑,这种做法同时减少了depthwise卷积的规模)。
同样,如果你对MobileNet v2的Bottleneck不熟悉的话,我之前写过一篇相关文章:
Yin Guobing
最后,作者在bottleneck的最前端又塞入了一层depthwise卷积。并增加了Max Pooling与Channel Padding作为可选旁路,并将这种结构命名为Double BlazeBlock。
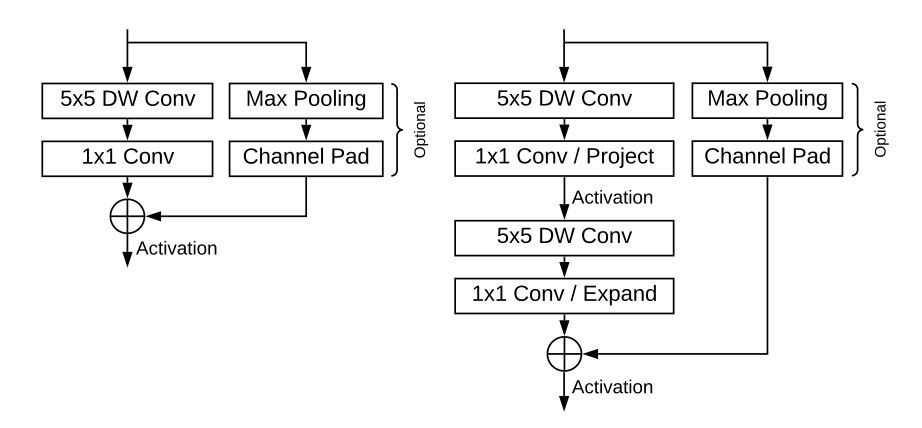
我觉得这个结构与MobileNet v2差别很大。先收缩后扩张的策略、额外增加的depthwise卷积层、Pooling旁路以及非线性激活的位置,很难说与MobileNet v2的Inverted Residuals and Linear Bottlenecks有什么联系。
特征提取部分
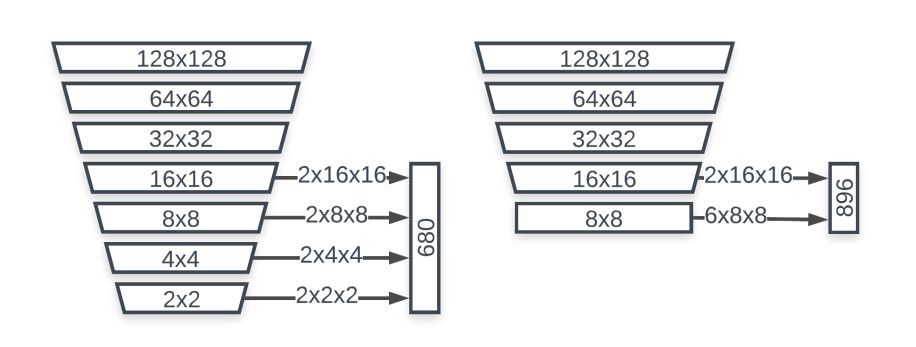
对于前置摄像头这种人脸占图像很大面积的场景,作者使用了128×128像素的RGB输入,后跟1个常规5×5卷积、5个BlazeBlock、6个Double BlazeBlock,其中通道数最大值为96。最后一层特征图尺寸为8×8,而SSD为1×1。
Anchor机制
BlazeFace的特征提取网络在特征图缩小到8×8时就结束了。作者给出的理由是“Pooling Pyramid Network (PPN) 表明特征图在达到特定分辨率后的附加运算存在冗余”。另外作者指出:在GPU上调度特定运算层存在可察觉的固定损耗,尤其是针对CPU优化的深度低分辨率网络层。综合以上两点,BlazeFace网络的深度止步在8×8大小,但是将anchor的数量扩增到了6个。同时考虑人脸相对固定的形状变化,将anchor的比例固定在1:1。
后处理
由于8×8特征图上扩增了anchor数量,大量的检测结果会重叠在一起。传统的处理方式是使用NMS。作者提出使用融合(blending)而非抑制(suppression)策略。具体的做法为将重叠边界框回归参数做加权平均计算,而NMS则是采用重叠结果中的一个。
总结
专注主题,这里不再列出测试结果,您可以下载原文查阅具体的数据。总体来看,BlazeFace是一款针对手机AR提出的、应用场景非常明确、高度定制化的人脸检测方案。例如昨天的人脸网格AttentionMesh应用就使用它来获得面部区域。BlazeFace的提出并非要取代其它人脸检测框架。对于移动端模型开发来说还是有不少可以参考借鉴的地方。
论文的下载地址:


Comments ()