解读Google的人脸网格方案Attention Mesh
一个网络实现分而治之的策略

在上一篇文章中我们介绍了Google 3D人脸网格的具体实现过程,如果你还没有看过的话推荐先看完上篇,地址如下:
 Yin Guobing
Yin Guobing
本次要解读的文章同样来自Google,发表于2020年,标题为 Attention Mesh: High-fidelity Face Mesh Prediction in Real-time, 可以视作上篇文章方案的改进。为了行文方便,以下分别使用方案1与方案2指代这两篇文章。
本次解读的文章下载地址如下:
https://arxiv.org/pdf/2006.10962.pdf
方案改进点
方案1中,图像首先经过人脸检测器处理,面部区域被裁剪出然后送入一个单一神经网络回归特征点。作者认为该方法会对局部区域的细节推演造成不利影响,并指出将区域分割后送入多个专用神经网络分而治之的级联(cascaded)方案虽然可以解决准确度问题,但是以性能作为代价。
为此作者提出针对特定面部区域构建网络分支并使用空域变换器(spatial transformers)来对特征图做出变换。这样检测准确度可以媲美级联方式,而速度又有30%左右的提升。作者将该方案命名为注意力网格(attention mesh),并指出此种方式在应对面部突出区域时有着出色的表现。
网络架构
网络的输入为256×256像素的面部区域。在获得64×64大小的特征图之后,模型分裂为若干子模型。其中一个模型负责预测478个3D网格顶点坐标(方案1为468个,这是一个不同之处)以及每个感兴趣区域的裁切边界。其余的子模型负责在注意力机制下获得的24×24大小的特征图上预测关键点坐标。
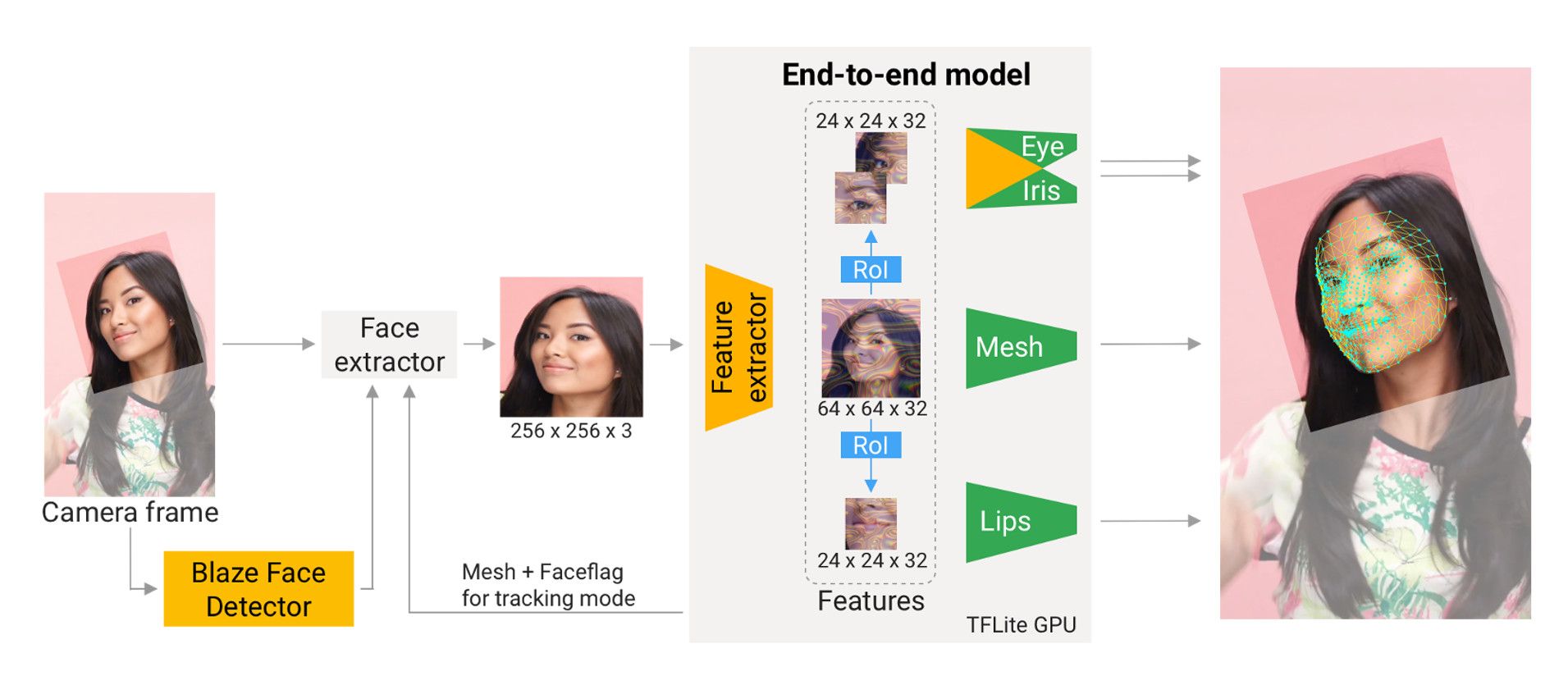
作者特别强调了面部的三块区域:嘴唇与双眼。尤其是双眼,瞳孔预测是在6×6特征图之后,这样可以将动态的瞳孔与相对固定的眼周分离开。为了增强每个子模型的准确度,作者引入归一化以确保双眼与嘴唇在垂直方向上是对齐且大小均一。
训练过程
模型的训练分为两个阶段。第一个阶段从标准数据裁切并做轻度增强后训练所有的子模型。第二个阶段则利用模型本身的预测结果来裁切并训练。
注意力机制
这里的注意力机制具体的做法为:在特征空间上设置二维网状采样点,并使用二维高斯核或者仿射变换与微分差值(differen-
tiable interpolations)在采样点对应的特征图上提取特特征。作者使用了空间变换从64×64大小的特征图上提取24×24大小的局部特征。
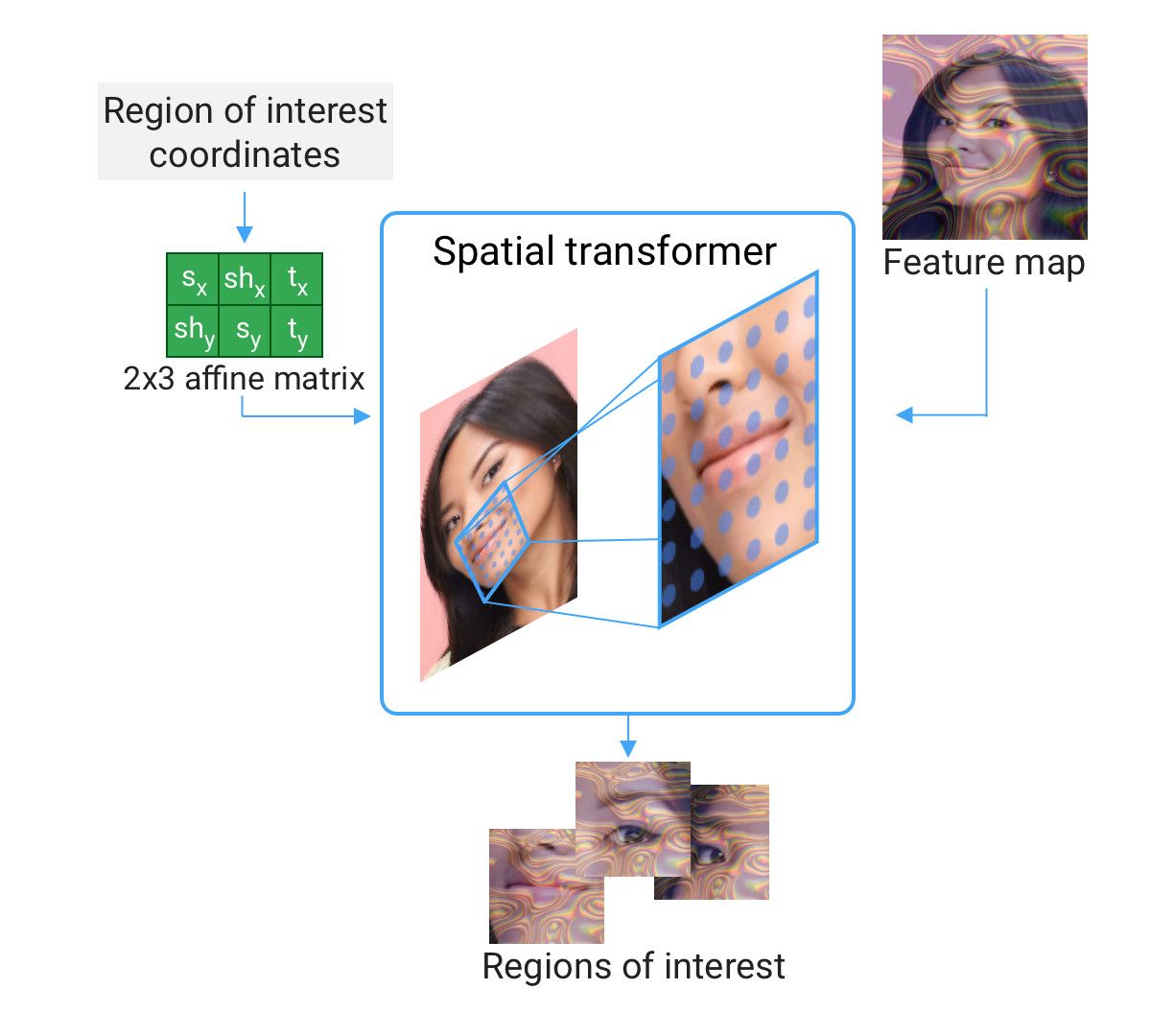
空间变换的具体操作由变换矩阵 $\theta$ 来实现:
$$ \theta=\begin{bmatrix}
x_{x} & sh_{x} & t_x \\
sh_{y} & s_{y} & t_{y}
\end{bmatrix} $$
仿射变换的实现可以通过对变换矩阵的有监督学习,或者通过面部网格子模型的输出来获得。(这里我没有看懂。仿射变换是要拿到CPU里去算?还是神经网络直接实现?)
数据集
与方案1相同。
测试结果
作者采用了与方案1相同的测试规则,只不过对比的对象为级联方案。具体的数值不在这里展开。感兴趣的小伙伴可以去Github亲自试用,地址如下:

个人看法
这篇文章作为2019年文章的延续,最大的创新点应当是针对面部重点区域采用分而治之的策略,并使用单一网络的不同分支来实现。在“分”的过程中引入了注意力机制,通过仿射变换提取局部特征。如果要复现的话,网络模型的构建应当是难点所在。
微信扫一扫分享


评论 ()