图解MobileNetV2中的Bottlenecks
MobileNetV2中使用了一种名为Inverted Residuals and Linear Bottlenecks的结构,解决了V1版本中SeprableConv存在的输入层Kernel数量固定的瓶颈。

MobileNets的核心Separable Convolution可以在牺牲较小性能的前提下有效的减少参数量[1]。但是它也存在局限,表现为Depthwise卷积的Kernel数取决于上一层的Depth,无法随意改变。MobileNetV2克服了这一局限[2]。
扩增输入通道数
在之前的博客中已经分析了Separable Convolution与传统卷积的差异[3]。Separable Convolution将传统的卷积运算用两步卷积运算代替:Depthwise convolution与Pointwise convolution,如下图所示。
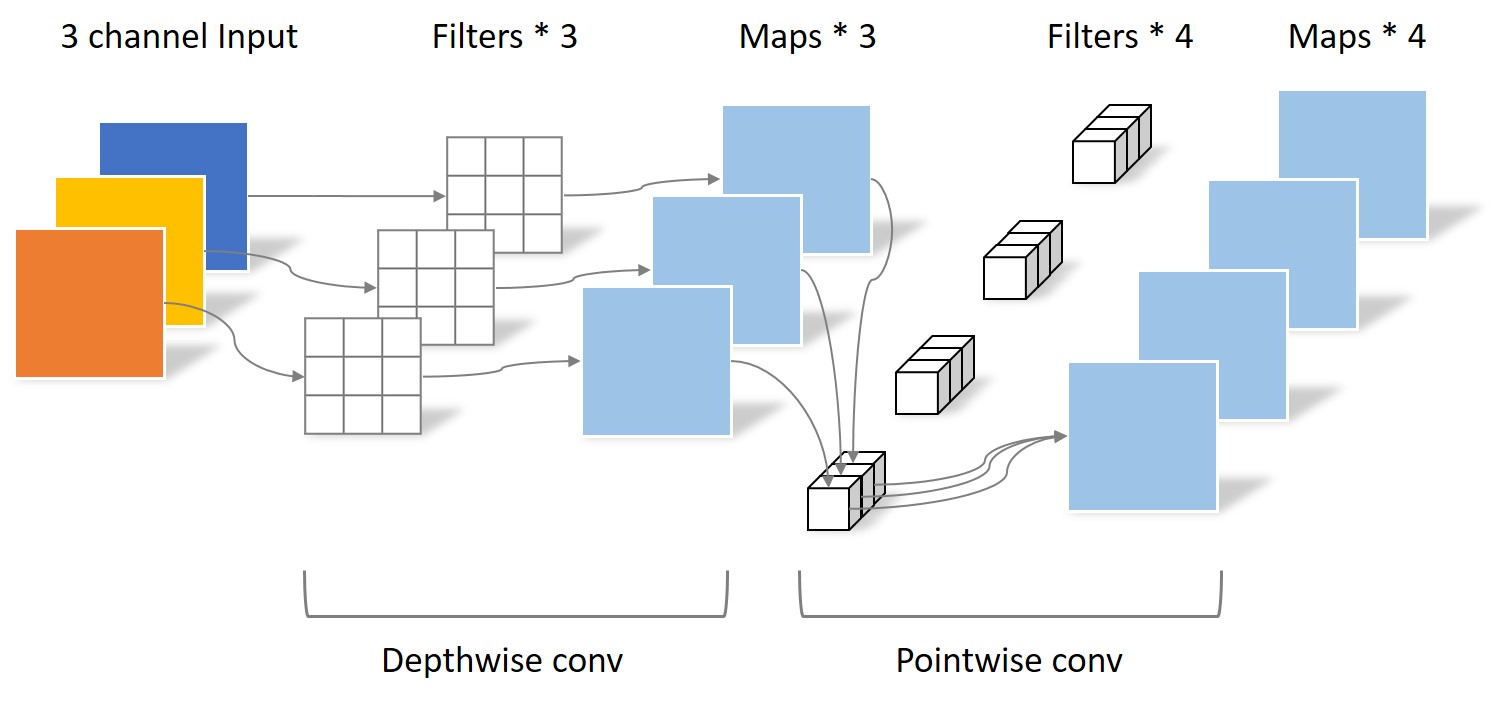
从图中可以明确的看出,由于输入图片为RGB三通道,Depthwise conv的Filter数量只能为3。Depthwise convolution的Filter数量局限于上一层的输出通道数,无法自由改变。
MobileNetV2在Depthwise convolution之前添加一层Pointwise convolution,如下图所示。
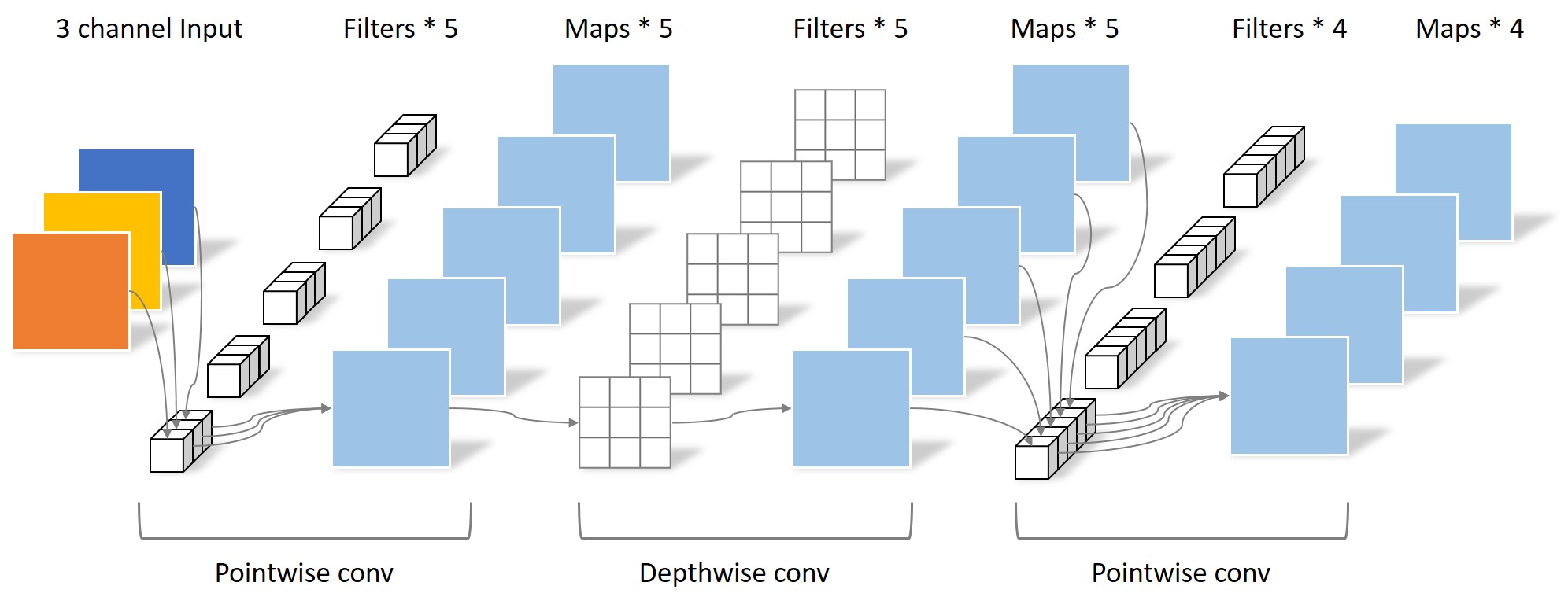
添加了这一层Pointwise convolution之后,Depthwise convolution的Filter数量取决于之前的Pointwise的通道数。而这个通道数是可以任意指定的,因此解除了3x3卷积核个数的限制。
特定层不使用非线性激活
MobileNetV2与传统的Separable convolution不同的地方还包括第一次Pointwise与Depthwise均使用了非线性激活函数ReLU6,但是第二次Pointwise则不采用非线性激活,保留线性特征。对此作者解释如下:
- If the manifold of interest remains non-zero volume after ReLU transformation, it corresponds to a linear transformation.
- ReLU is capable of preserving complete information about the input manifold, but only if the input manifold lies in a low-dimensional subspace of the input space.
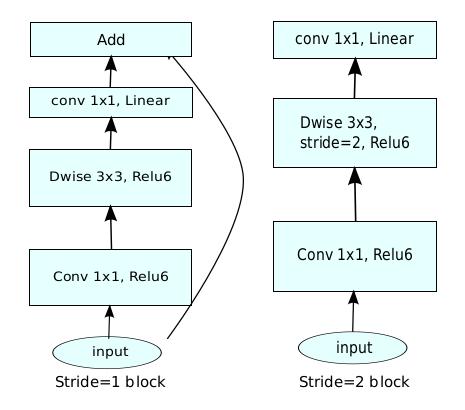
增加Residuals连接
MobileNetV2在特定的Block里加入了残差连接。将输入与输出直接进行相加。下图来自作者论文。这样可以使得网络在较深的时候依旧可以进行训练。
TensorFlow实现
TensorFlow已经内置了MobileNet所需要的Separable Convolution[4],但是由于非线性激活函数的不同,无法直接用于MobileNetV2。好在构成Bottlenet block的Depthwise convolution是可用的[5],因此可以在此基础上自己手动搭建一个。在这里放一个我自己的实现,比较潦草,希望能提供一些思路。
def make_bottleneck_block(inputs, expantion, depth, kernel=(3, 3)):
"""Construct a bottleneck block from a block definition.
There are three parts in a bottleneck block:
1. 1x1 pointwise convolution with ReLU6, expanding channels to 'input_channel * expantion'
2. 3x3 depthwise convolution with ReLU6
3. 1x1 pointwise convolution
"""
# The depth of the block depends on the input depth and the expantion rate.
input_depth = inputs.get_shape().as_list()[-1]
block_depth = input_depth * expantion
# First do 1x1 pointwise convolution.
block1 = tf.layers.conv2d(
inputs=inputs,
filters=block_depth,
kernel_size=[1, 1],
padding='same',
activation=tf.nn.relu6
)
# Second, depthwise convolution.
depthwise_kernel = tf.Variable(
tf.truncated_normal(shape=[kernel[0], kernel[1], block_depth, 1], stddev=0.1))
block2 = tf.nn.depthwise_conv2d_native(
input=block1,
filter=depthwise_kernel,
strides=[1, 1, 1, 1],
padding='SAME'
)
block2 = tf.nn.relu6(features=block2)
# Third, pointwise convolution.
block3 = tf.layers.conv2d(
inputs=block2,
filters=depth,
kernel_size=[1, 1],
padding='same'
)
block3 = tf.add_n([inputs, block3])
return block3
MobileNets: https://arxiv.org/abs/1704.04861 ↩︎
MobileNetV2: https://arxiv.org/abs/1801.04381v1 ↩︎
/separable-convolution/ ↩︎
https://tensorflow.google.cn/versions/master/api_docs/python/tf/layers/SeparableConv2D ↩︎
https://tensorflow.google.cn/versions/master/api_docs/python/tf/nn/depthwise_conv2d ↩︎
微信扫一扫分享



评论 ()