缩放自如的EfficientDet
有没有一个统一的物体检测框架,能够满足不同运算规模设备的需求

封面图片:David Clode
EfficientDet是由Mingxing Tan,Ruoming Pang与Quoc V. Le在2019年的文章EfficientDet: Scalable and Efficient Object Detection提出的一种物体检测方案。名字应该是衍生自efficient detector,不难看出效率是它的主要亮点。
本文为该文章的学习笔记。你可以在这里找到全文。
在不断追逐准确率的过程中,物体检测模型的规模也在迅速上升。例如NAS-FPN detector的运算量达到3045 BFLOPs,是RetinaNet的30倍还多。庞大的规模限制了它们的使用场景,为此有众多的优化模型被开发出来。但是这些优化模型多以局限的运算资源为开发背景,例如移动设备。有没有一种可以缩放的方案,能够在较宽的设备谱上同时具备高准确率与高效率?
为此作者在one-stage检测器的基础上研究了骨干网络、特征融合、分类与边框回归网络,来尝试应对两大挑战:
- 更高效的多尺度特征融合。此前基于FPN的多尺度特征融合大多是简单的相加。但是作者发现不同尺度的特征图对于融合后的输出特征贡献是不同的。为此作者提出了双向特征金字塔网络(BiFPN),来学习不同尺度特征图的重要性。
- 模型缩放。此前的工作多将注意力放在骨干网络的缩放上。但是作者发现特征提取网络、分类与边框回归网络的缩放也同等重要。为此作者提出了复合缩放来同步缩放全部网络。
最后,在骨干网上作者选用了EfficientNet,结合以上两点,形成了EfficientDet。
双向FPN
如果你不知道什么是FPN的话,可以先阅读这篇文章:
 Yin Guobing
Yin Guobing
FPN最先提出时是为了解决小尺度物体检测结果不佳的问题。其解决思路是将神经网络高层特征逐级向下融合到下层特征图中。如下图(a)所示。
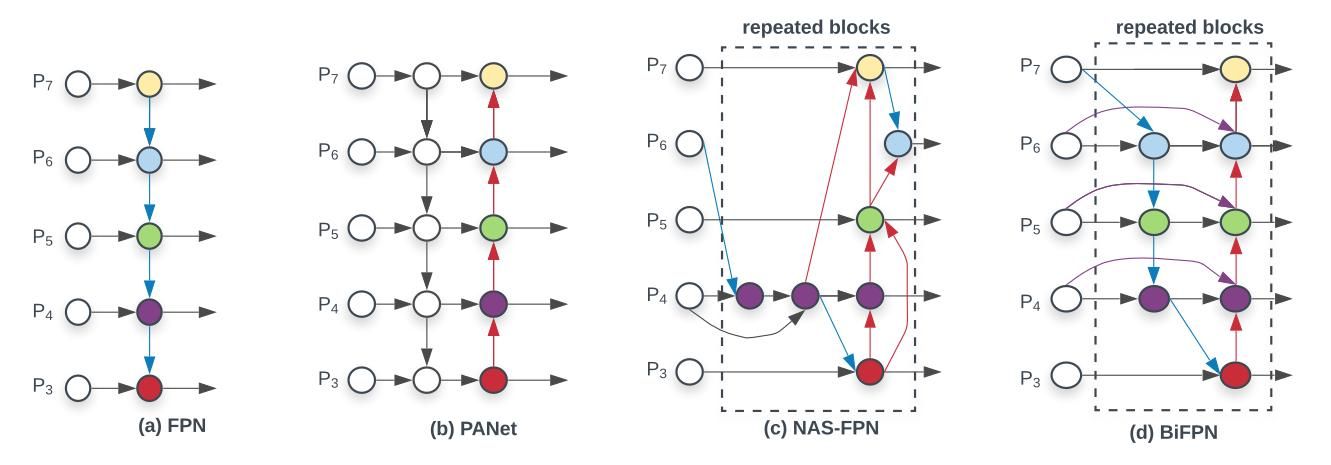
为了增加信息交流的程度,PANet在FPN这种由上至下的单向流动基础上增加了右下至上的特征融合,形成双向融合,如图(b)所示。进一步的,NAS-FPN通过架构搜索的方式获得了更加复杂的特征融合方式,如(c)所示。作者在研究后发现,a、b、c三种结构中,PANet(b)能够获得更佳准确率,但以更多的参数与运算为代价。
在PANet的基础上,作者的改进思路为:第一,移除只包含单个输入的节点。原因为作为特征“融合”网络,单输入的节点与融合没啥关系。第二,增加同层级的输入节点到输出节点的连接。我觉得这一点与ResNet的思路几乎一致。第三,作者将这个结构不断重复堆叠,实现了特征的多次融合。这个让我想起来HRNet,不过HRNet的层级逐渐递增,双向FPN则保持不变。
双向FPN的另一个不同之处在于差异化的处理各层特征。每一层特征对最终的融合结果需要经过可学习的参数加权处理。作者命名为fast normalized fusion。
最后,将骨干网络、重复多次的双向FPN与分类/边框回归网络组合在一起,便构成了EfficientDet。
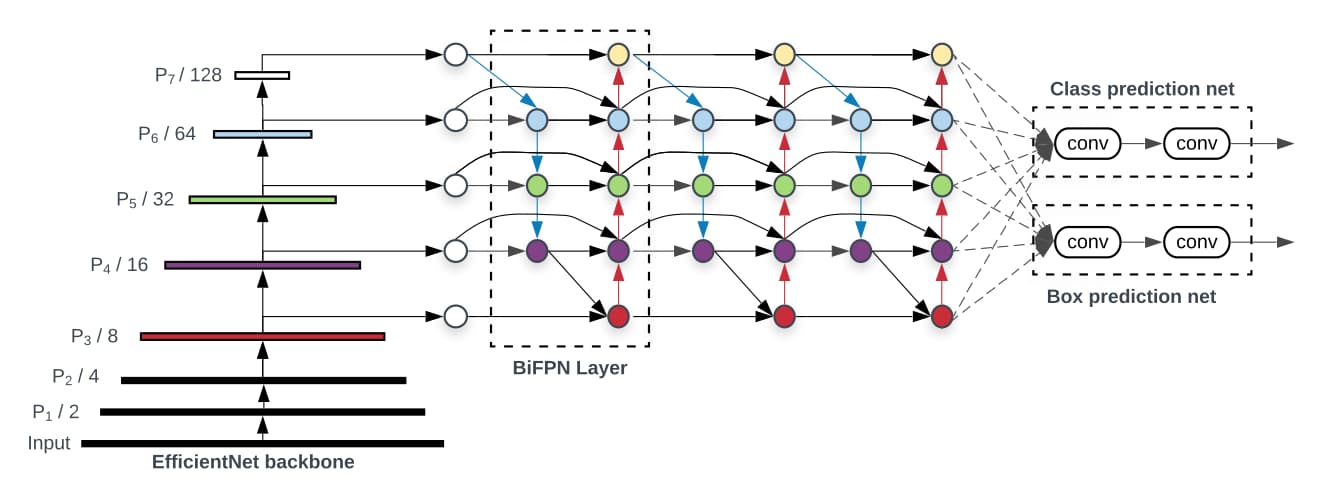
复合缩放
之前的物体检测框架在缩放规模时多采用增大骨干网络规模、扩大输入图像尺寸,堆叠更多的FPN层等方法。作者认为这些方法缩放的维度局限因为效果不佳。受EfficientNet的启发,作者使用复合参数φ在全部维度上联合缩放骨干网络、双向FPN、分类与边框回归网络以及分辨率。
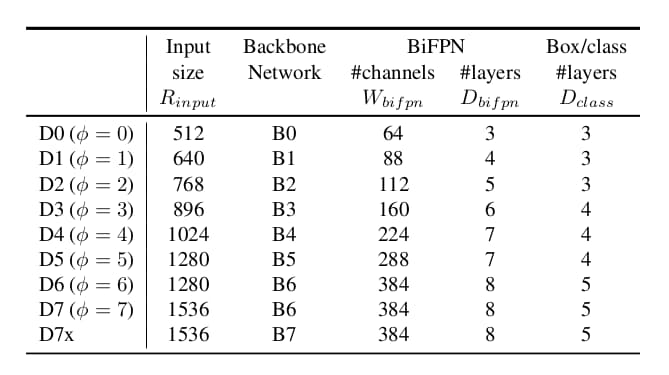
- 骨干网络。使用EfficientNet-B0-B6相同的缩放参数,以便再利用ImageNet预训练权重。
- 双向FPN网络。双向FPN的层数以线性的方式增加。而其通道数则以指数方式 64*1.35φ 增加。经过一番搜索后缩放因子为1.35。
- 分类与边框回归网络。通道数与双向FPN保持一致。层数则以3+3/φ的形式变化。
- 输入分辨率。由于双向FPN的存在,输入分辨率必须被 27 整除。所以输入分辨率等于512+φ*128。
最后,参数φ的取值从0到7,得到7个规模的EfficientDet。注意最小规模的输入尺寸为512,最大的为1536。
训练细节
EfficientDet在COCO数据集下训练,包含118K张图像。优化器为SGD、momentum等于0.9,weight decay为4e-5。学习率在第一个epoch从0增大至0.16,之后cosine decay rule减小。每个卷积层后跟随synchronized batch norm,decay为0.99,epsilon为1e-3。激活函数为SiLU。权重参数使用exponential moving average,decay为0.9998。损失函数为focal loss,α = 0.25,γ = 1.5。Anchor的比例{1/2, 1, 2}。
训练中使用数据增强:水平翻转、抖动缩放[0.1, 2.0]。测试时使用soft-NMS。模型D0-D6训练300个epoch,batch size为128。训练设备为32个TPU v3核心。我查了下一个TPU v3核心内存为16GB。深度学习已然沦为了大佬的游戏。
结论
EfficientNet + 双向FPN + 复合缩放,这就是EfficientDet的核心秘密。在我的RTX 3090上,EfficientDet-D0的检测速度可以跑到40FPS。你可以在这里看到示例视频:
 真诚友善硬核的流浪AI
真诚友善硬核的流浪AI
如果你想自己尝试一下,可以参考这个开源项目:
 yinguobing
yinguobing另外作者文章中还有其它大量的细节可以参考,如果你感兴趣可以继续阅读全文。


Comments ()