物体检测中的特征金字塔
如何更好的检测多尺度物体

Photo by AussieActive on Unsplash
这是一篇来自Facebook AI Research的文章,主要描述了特征金字塔网络Feature Pyramid Network(简称FPN)在特征提取任务中的优秀表现。你可以在这里找到原文:
以下为对该文章核心内容的摘抄,注意在某些部分有我自己的理解。
如何识别大尺度范围的物体是计算机视觉的一项基础挑战。基于图像金字塔构建的特征图像金字塔曾是这一问题的标准解决方案。考虑物体的尺度变化体现在金字塔层级的切换上,这一类金字塔可以认为是与尺度无关的。这种性质使得通过扫描不同位置与不同金字塔层级即可实现大尺度范围的物体检测。
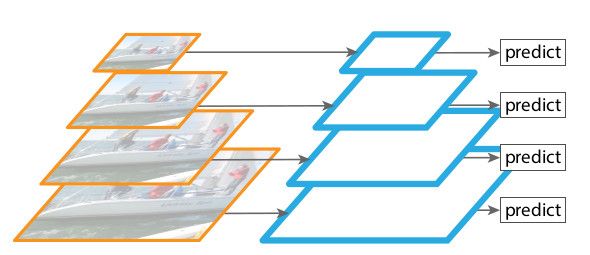
特征图像金字塔在手工设计特征的时代被广为使用,但是目前大多被卷积神经网络所取代。卷积神经网络不仅可以表达高阶语义特征,在面临物体尺度变化时的表现也更加稳健,继而催生了基于单一尺度输入的特征识别。
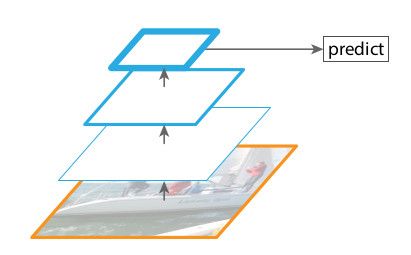
但是即便考虑到卷积神经网络的稳健特性,要想获得更加准确的结果依旧离不开金字塔型分布。针对金字塔图像每一层的特征化可以生成高度语义化的多尺度特征表达,包括分辨率最高的层级。
诚然,对图像金字塔的每一层实施特征化存在明显的不足,例如运算时间的显著增加,使得这一方法难以在实际中应用。进一步,利用图像金字塔训练神经网络带来的内存压力也限制了它的应用。
然而,图像金字塔并非获得多尺度特征表达的唯一方式。深度卷积网络计算得到的特征就呈现出层级分布,并且降采样层的应用使得特征分布天生表现出多尺度的金字塔形态。这种内置于网络的特征架构能够产生不同空间分辨率的特征图,但是造成了不同深度之间的语义鸿沟。高分辨特征图所具有的低阶特征限制了针对物体识别的表达能力。
SSD尝试将卷积神经网络的金字塔特征层当做特征图像金字塔来使用。理论上,这类方案应当再利用前向传播时获得的不同层级多尺度特征图以避免额外的运算消耗。但是为了避免使用低层级特征图,SSD在原有网络的基础上加盖了特征金字塔,引入了更多层级。因此它错过了使用高分辨率特征图的机会,而这对于小尺度物体的检测却非常重要。
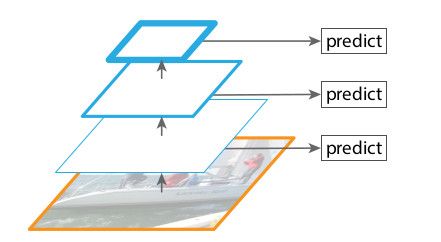
FPN的目标为:基于卷积神经网络特征层天然的金字塔形态,构建所有层都富含语义的特征金字塔。为达成这一目标,作者将低分辨、强语义特征层与高分辨、弱语义特征层通过由上至下的路径以及横向连接组合起来,获得了在所有层级都具备丰富语义信息且仅需要单一尺度输入图像的特征金字塔。一个可以取代特征图像金字塔、内置于网络的特征金字塔——FPN。
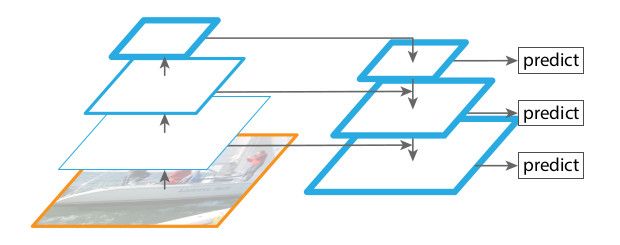
过往与此类似的架构设计多以生成单一精细高阶图为目标,并在此基础上执行下一步操作。而FPN的后续操作在多个层级的特征图上执行。
相关工作
早期的手动设计特征方案如SIFT与HOG需要应用在整个图像金字塔上。针对该类方案的优化集中在快速生成图像金字塔上。OverFeat将卷积神经网络与滑动窗口配合在图像金字塔上使用。R-CNN的区域提取方案会将提案对象在尺度上归一化。SPPnet则展示了基于单一尺度图像的特征图建议区域效率更高。Faster R-CNN推崇基于单一尺度的计算,认为这样取得了精度与速度的均衡。然而多尺度的方案依旧表现的更好,尤其是针对小尺度物体。
FCN的语义分割将多个尺度的局部评分累计起来。HyperNet、ParseNet、ION则在计算结果前会将多个层级的特征拼接起来。SSD与MS-CNN则在多个层级的特征图上做出推演,而不会将特征或者分数结果组合。
U-Net、SharpMask、Recombinator、Stacked Hourglass都使用横向连接或者跨越连接。这些方案都有着类似金字塔形态的架构,但是并没有像特征图像金字塔一样在每一层独立执行推演。对于某些方案,依旧需要图像金字塔来识别多尺度物体。
特征金字塔
特征金字塔以任意尺寸的单尺度图像为输入,通过全卷积的方式输出尺寸成比例的多层级特征图。该过程独立于骨干网络。特征金字塔的构建涉及到一个由下至上通道、一个由上至下通道以及横向连接。
由下至上通道
该通道的本质是骨干网络的前向传播路径,包含若干不同尺度、缩放因子为2的特征图。若网络中存在多层相同尺寸的特征图,则取最后一层。例如ResNet中的conv2、conv3、conv4、conv5,并记为 {C2, C3, C4, C5}。这几层相对于输入图像的strides值为{4, 8, 16, 32}。conv1层太大,因此不考虑。
由上至下通道与横向连接
由上至下通道是由金字塔上部语义更强、分辨率更低的特征图上采样获得的。之后横向连接将与之对应的由下至上通道的特征图相融合。
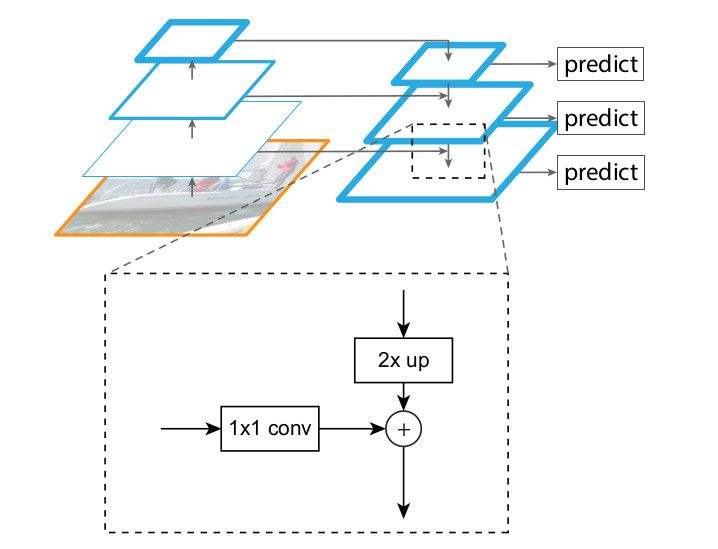
上图展示了横向连接的运作方式。首先通过最近邻上采样将低分辨特征图尺寸扩大2倍,之后使用1×1卷积匹配通道数,最后按元素相加。在由上至下路径中,顶端的低分辨特征图由1×1卷积生成。最终的特征图则是在每张融合后的特征图上执行3×3卷积后获得,以规避上采样的“对齐效应”。最终生成的特征图记为{P2, P3, P4, P5}。如同传统的特征图像金字塔,所有金字塔层级共享分类与回归网络,所以将特征图的通道数固定为256。这些额外的卷积层不包含非线性激活层。
在RPN中使用
在FPN的每一层使用3×3卷积与1×1卷积作为head。由于head在金字塔所有层级上稠密滑过,所以不需要使用多个anchor scale。对于特征金字塔的{P2, P3, P4, P5, P6},对应anchor的面积被固定为{322, 642, 1282, 2562, 5122}像素。同时将anchor的宽高比定位 {1:2, 1:1, 2:1}。总计获得15个anchor。Anchor与实际边界框的匹配取决于IoU,以0.7为阳性判定阈值,0.3为阴性判定阈值。作者还发现分类与回归head的权重是否共享影响并不大。这证明特征金字塔的所有层的语义层级是相似的。这些参数也是RetinaNet anchor的来源,不过RetinaNet增加了3个scale。
在训练中,输入图像被缩放,使得短边长为800像素。优化器为SGD,在8个GPU上执行。每个mini-batch包含16个图像,每张图像256个anchor。weight decay为0.0001、momentum为0.9。初始学习率为0.02,30k step之后为0.002。另外超过图像范围的anchor也用在了训练中。COCO数据集的训练花费了8个小时。
(文章中还有大量实验数据,这里不再作为核心内容列出)
结论
特征金字塔的提出使得卷积神经网络不再需要计算图像金字塔。然而类似金字塔形态的表达对于解决多尺度问题依旧重要。
微信扫一扫分享
有技术问题需要解决?
论文复现、模型部署、代码审查 —— 把问题带来,我帮你走通整条链路。
 关于我
关于我



评论 ()