YOLO如何一招制胜
You only look once.

封面图片:Susn Matthiessen on Unsplash
上一篇文章“R-CNN进化论”介绍了R-CNN系列如何从零开始逐步将深度学习引入到物体检测框架中。也许你还对检测速度是如何从最初的47秒下降到小于1秒有映像。本篇文章中你会了解到另一种以速度闻名的深度学习物体检测方案——YOLO。

YOLO是由华盛顿大学的Joseph Redmon等人(有趣的是R-CNN作者Ross Girshick是第三作者)最早在文章“You Only Look Once: Unified, Real-Time Object Detection”中提出的一种实时物体检测方案。很显然YOLO的名字也出自这篇文章。YOLO最大的特点是快——相比Faster R-CNN的0.2秒,它可以做到0.02秒以下,基本可以用实时检测来描述。以下内容是我对作者文章核心内容的摘抄,如果是我个人的观点会单独注明。
YOLO:我只看一次
R-CNN速度缓慢,是因为它的检测流程太过复杂。YOLO的出发点是将物体检测转化为从图像到边界框与类别概率的回归任务。且整个过程中,“你只看一次(You only look once)”。
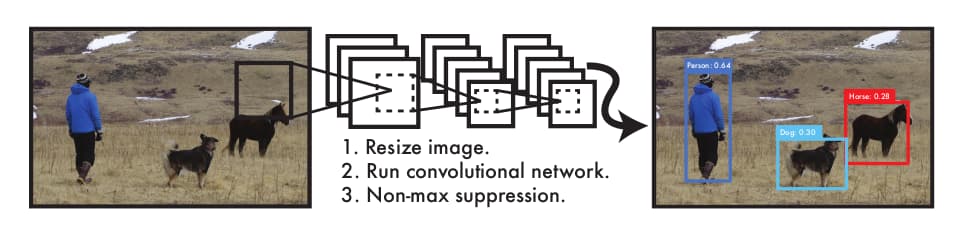
因此YOLO执行起来非常迅速,基本款在Titan X GPU下能跑在45 FPS,加速款可达150 FPS。此外与Fast R-CNN相比,YOLO的决策是在神经网络在完整输入图像的基础上做出的,因此检测失误的概率更小。最后,YOLO学习的是物体的泛化特征,这意味着它在迁移到其它领域或者面临不确定输入时奔溃的概率更小。不过YOLO并不完美,在检测准确率与小尺寸物体方面仍面临不足。这些在后续会有讨论。
从上传到Arxiv手稿的初版日期来看,YOLO只比Faster R-CNN晚4天,这也许是作者在文章中大量拿Fast R-CNN而非Faster R-CNN来分析对比的原因。
统一检测架构
也许你还记得R-CNN是如何将物体检测划分为3个功能模块。YOLO则将这些模块统一在一个神经网络网络中。
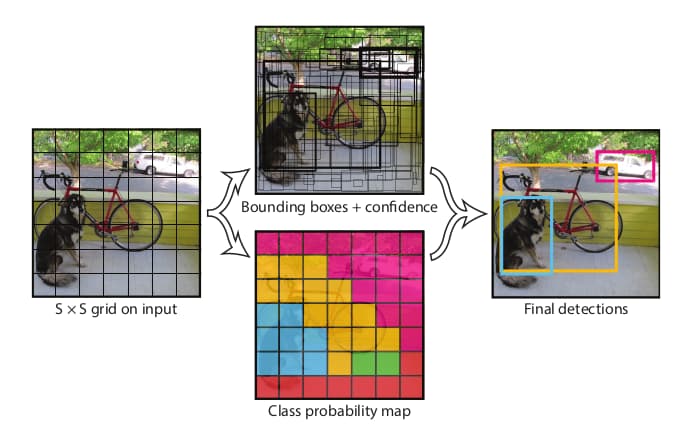
首先输入图像被尺寸为S×S的网格分割。如果物体的中心落在某个格子中,则该格子负责检测该物体。每个格子需要预测B个边界框以及相应的置信度。置信度的数值反映了模型对该格子包含物体以及格子预测准确率的信心。更正式一点的表述可以记为:
$$C = Pr_{object} \times IoU_{pred}^{truth}$$
如果该格子不包含任何物体,则置信度为0;如果包含任一物体,则置信度为预测边界框与实际边界框的交并比(IoU)数值。
每个边界框由5个变量组成:$x, y,w, h$与置信度。$(x, y)$是边界框中心与网格边界的相对值。宽度与高度是与图像尺寸的相对值。置信度则等同于边界框预测值与实际值的IoU。
每个格子同时要预测C个分类的条件概率 $Pr(Class_i|Object)$。这里的概率为条件概率——该格子包含物体。无论边界框B的数量是多少,每个格子都只输出一种类别。运行时将分类条件概率与格子的置信度相乘即可给出每个格子针对某个类别的置信度。
$$Pr(Class_i|Object) \times Pr_{object} \times IoU_{pred}^{truth}$$
该置信度同时反映了该格子包含某类别物体以及边界框与物体重合程度的好坏。
针对PSACAL VOC数据集的设定中,S=7、B=2、C=20。所以最终的输出为7×7×30的张量。
网络架构
YOLO的网络架构受用于图像分类的GoogLeNet启发,包含24个卷积层与2个全连接层。与Inception module的不同之处在于仅包含1×1降采样与3×3卷积。完整架构如下图所示。
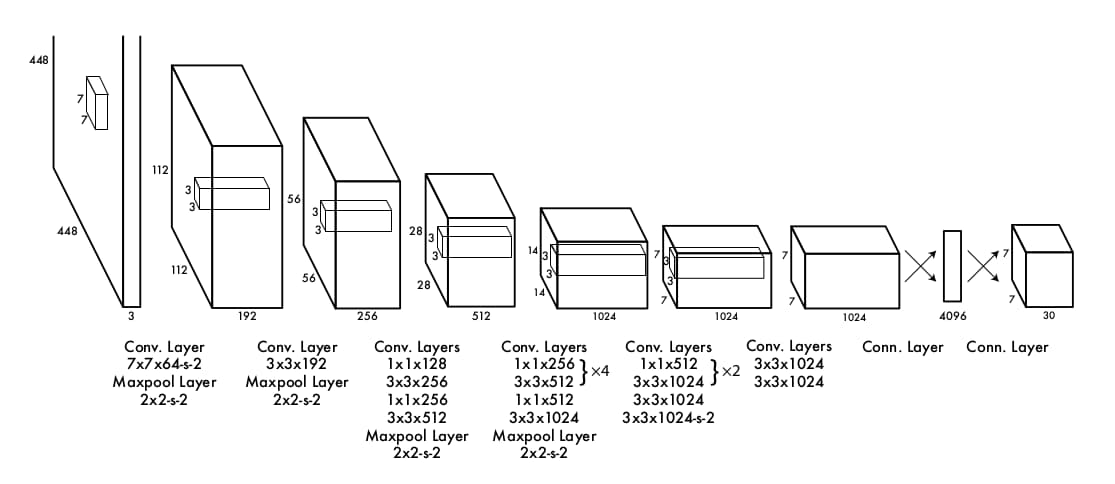
作者还设计了一款加速版YOLO。它的卷积层数从24下降到9,并且filter的数量也更少。除此之外其它参数与基本款相同。
训练
YOLO首先在ImageNet上执行了预训练,且预训练仅限前20层卷积层。考虑到物体检测需要精细的视觉信息,输入尺寸设定为448。最后一层输出类别概率与边界框坐标。边界框的长宽基于图像尺寸归一化。边界框的坐标x、y则基于特定网格的位置偏移归一化。最后一层使用线性激活函数,其它层使用leaky ReLU。
$$ \phi(x)=\begin{cases} x, & \text{if } x>0 \\ 0.1x, & \text{otherwise}\end{cases} $$
损失函数使用了平方和误差,然而却面临一系列问题:定位误差与分类误差均等对待;大量不包含物体的网格(负样本)会挤压包含物体的网格(正样本)的梯度值,导致模型在早期发散。为了解决这一问题,作者引入了权重参数$\lambda_{coord}=5$与$\lambda_{noobj}=0.5$。
平方和误差同等对待大尺寸与小尺寸边界框,然而小尺度的偏移对于大尺寸边界框的影响应当弱于对小尺寸边界框的影响。为此模型不直接输出边界框的宽高,而是宽高的平方根。
YOLO的每个网格需要输出多个边界框。训练时,每个物体理想状态下应当仅匹配一个边界框,通过筛选IoU最大值来实现。这使得多个边界框的预测有了倾向性。
最终的损失函数可以记为:
$$\lambda_{coord}\sum^{S^2}_{i=0}\sum^B_{j=0}\mathbb{I}_{ij}^{obj}[(x_i-\hat{x}_i)^2 + (y_i - \hat{y}_i)^2] \\ + \lambda_{coord}\sum^{S^2}_{i=0}\sum^B_{j=0}\mathbb{I}_{ij}^{obj}[(\sqrt{w_i}-\sqrt{\hat{x}_i})^2 + (\sqrt{h_i}-\sqrt{\hat{h}_i})^2] \\ + \sum^{S^2}_{i=0}\sum^B_{j=0}\mathbb{I}_{ij}^{obj}(c_i-\hat{c}_i)^2) \\ + \lambda_{noobj}\sum^{S^2}_{i=0}\sum^B_{j=0}\mathbb{I}_{ij}^{noobj}(c_i-\hat{c}_i)^2 \\ + \sum^{S^2}_{i=0}\mathbb{I}_{i}^{obj}\sum^B_{c\subset classes}(p_i(c)-\hat{p}_i(c))^2 $$
其中$\mathbb{I}_{i}^{obj}$代表格子$i$有物体出现,$\mathbb{I}_{ij}^{obj}$代表$i$格子的第$j$个边界框负责该物体的检测。这使得损失函数有了选择性。
训练总epoch数为135,batch size为64。第一个epoch学习率从10-3 缓慢上升至10-2,如果初期的学习率过大容易导致模型发散。之后保持该学习率至75个epoch,然后降低至10-3 并持续30个epoch,最终降低至10-4 持续30个epoch。
为防止过拟合引入了0.5比例的dropout与数据增强,相对原始图像尺寸20%的随机缩放与偏移,以及随机曝光和HSV色彩空间内1.5因子的随机饱和度增强。
推演
YOLO的设计使得推演时网络仅仅需要以此前向传播即可。网格的设计确保了边界框的分散覆盖。然而一些特大尺寸物体或者接近于网格边界的物体会被多个网格预测到。此时可以通过NMS来消除多余的越策结果。
YOLO的局限
由于每个格子仅能预测2个边界框且仅可以包含一个类别,YOLO的边界框设在空间上存在较强束缚。这使得它在预测临近物体的数量上存在不足,例如鸟群。
另外边界框的学习完全来自于训练数据,所以当面临全新的或者有特殊形状比例的物体时表现欠佳。
最后,大尺寸边界框与小尺寸边界框对损失函数的影响是等同的,然而实际中同样的误差对小尺寸边界框的IoU影响明显更大。误差的主要来源是错误的位置检测。
与其它物体检测方案的比较
与DPM相比,YOLO没有滑窗,使用单体神经网络替代了多个独立的检测流程。与R-CNN相比,YOLO将全部功能集成在一个单体网络中,且提出的候选框只有98个,远小于R-CNN的2000个。与Faster R-CNN相比,YOLO的速度仍然快更多。Deep MultiBox仅算得上是检测流程中的一部分,不完整。OverFeat不是一个连续的检测系统,无法看到大局且需要大量的后处理。MutiGrasp无法给出物体的尺寸位置与类别。
小结
YOLO是一个统一于深度学习的物体检测架构。它在设计之初就全面以物体检测为目标,在实时物体检测领域获得优异结果,并且可以泛化到其它物体检测任务当中。有趣的是,YOLO与R-CNN系列类似也有续作,但要解决的问题不一样。
YOLO 9000:更高、更快、更强
YOLO 9000是第一篇续作,虽然它的名字起的像是上个世纪的某种家用电器,实际上这里9000的含义是YOLO v2可以检测9000种物体。
更高
YOLO的速度很快,但是以准确度作为代价。一种提升准确度的方法是引入更大容量的网络,但是作者并没有这么做。而是采用了如下措施:
- Batch Normalization。在所有卷基层后增加Batch Norm层,可以提升2% mAP。
- 高分辨输入。在预训练时就采用448×448分辨率的输入图像。
- Anchor Boxes。学习Faster R-CNN,引入Anchor boxes。取消所有polling层,输入设定为416,这样多层卷积之后图像缩小32倍,得到13×13特征图。同时分类任务与空间位置解耦,每一个anchor box都会得到分类。这样做mAP下降了0.3,但是recall提升了7%。
- Dimension Clusters。Anchor虽好但要用对。Anchor box的形状一般是手动设定。YOLO v2则采用k-means的方式对训练数据做了统计,得出更加合适的形状分布。
- Direct location prediction。这是anchor引入的第二个问题:模型早期不稳定,而主要原因在于(x, y)的确定。Faster R-CNN中x,y是通过预测偏移来实现的。而作者遵循了前代YOLO的设计,预测边界框相对于网格的位置,将数值限定在了0、1之间。与上一条改进联合,mAP提升5%。
- Fine-Grained Features。为了检测小尺寸物体Faster R-CNN与SSD都在大尺寸的特征图上执行检测运算。YOLO v2也引入了大尺寸特征图——23×23×512,但是将其转换为13×13×2048大小,并与最后一层特征图拼接。这样提升了1%的mAP。(我个人并不认同这种方案)
- Multi-Scale Training。训练时的输入图像尺寸为32的倍数:{320,352,...,608}。并且每10个batch就换一个输入尺寸。
更快
YOLO的网络设计受GoogLeNet启发,YOLO v2进一步改进如下:
- Darknet -19。19个卷积层与5个maxpooling层,batch norm、3×3卷积中嵌入1×1卷积等。进一步减少参数量。
- 迁移到检测。去除最后的卷积层。增加3×3×1024与1×1×输出数量的卷积层。
更强
这里的关键是分类数据与检测数据的联合训练。在具体实现时,如果输入为检测数据,则做完整的反向传播。如果输入为分类数据,则仅训练分类部分。这样做的难点在于分类数据是很多样的,例如检测数据可能标记为狗就结束了,但是分类数据可以细分到狗的物种名,如哈士奇等。此时就无法使用softmax分类,因为它假设类别之间是互斥的。
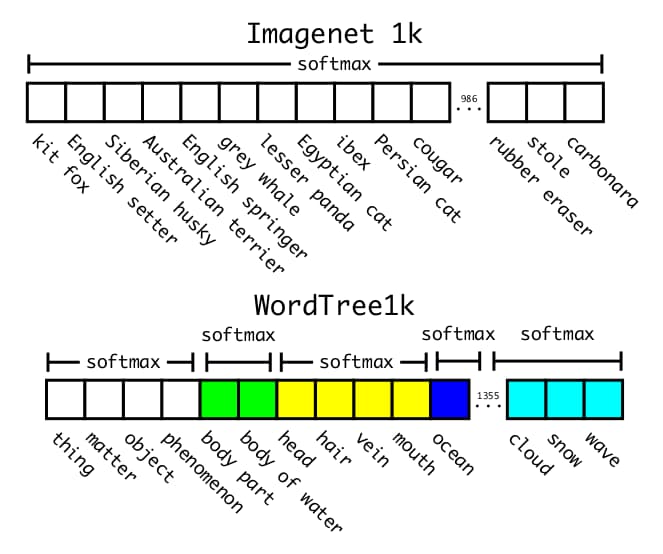
为解决这个问题,作者将ImageNet分类名词划分为树状结构构建了WordTree。例如“犬”下可以有3个分支:泰迪、贵宾、哈士奇。由于泰迪、贵宾、哈士奇是原有的分类名称,而“犬”实际上是新增的分类名称,结构化后的树状分类名总数为1369。而且分类的范围也因为树状结构被分块,由一个softmax变成多个softmax,如下图。
有了WordTree之后,就可以将不同的数据集的标签统一在WordTree之下,从而实现了多数据集训练。作者最终将COCO与ImageNet数据集联合起来,获得9000个分类。
小结
YOLO v2引入了其它网络验证的batch norm等方案提升了网络本身的表现能力。但是它最大的亮点还是在于通过WordTree的方式弥合图像分类数据集与图像检测数据集之间的裂缝。这种结构化的标签实际上可以考虑用在其它视觉任务中,毕竟信息分层的现象随处可见。
YOLO v3:渐进式改进
YOLO v3没有了YOLO 9000霸气侧漏的名字,但是文章的内容怎么看都显得有点“自由自在”!例如在开头作者首先对自己过去的一年时间做了个总结:
Sometimes you just kinda phone it in for a year, you know? I didn’t do a whole lot of research this year. Spent a lot of time on Twitter. Played around with GANs a little. I had a little momentum left over from last year; I managed to make some improvements to YOLO. But, honestly, nothing like super interesting, just a bunch of small changes that make it better. I also helped out with other people’s research a little.
然后给了读者一个大大的意外:
Actually, that’s what brings us here today. We have a camera-ready deadline and we need to cite some of the random updates I made to YOLO but we don’t have a source. So get ready for a TECH REPORT!
没有牵强附会的拔高自己,作者直接就明说了:
So here’s the deal with YOLOv3: We mostly took good ideas from other people.
相比一些论文明明创新性不够却卯足了劲地证明自己,YOLO作者太实诚了。
言归正传,YOLO v3中的改进包括:
边界框预测
与YOLO 9000类似,网络预测四个参数$t_x, t_y, t_w, t_h)$。当网格偏离图像原点$(c_x, c_y)$,且对应anchor的宽高为$p_w, p_h$时,预测边界框可以定义为:
$$x = \sigma(t_x) + c_x \\ y = \sigma(t_y) + c_y \\ w = p_we^{t_w} \\ h = p_he^{t_h}$$
对于IoU最大的边界框,赋值物体置信度1;对于剩余的边界框如果重叠区域小于特定阈值则忽略。
(与RetinaNet的anchor策略不同,YOLO始终预测边界框是否存在物体并用在loss反向传播中,哪怕没有匹配任何物体标签。)
分类
考虑到物体类别并非总是互斥的,使用二元交叉熵损失替代softmax。
跨尺度
类似FPN。从不同尺寸的特征图中执行运算以增强跨尺度表现。
特征提取
骨干网络更新为DarketNet-53,是的,53层网络。与之前的最大差异还体现在引入了ResNet中的残差链接。
训练技巧
与YOLO v2大致相同,多尺度训练,数据增强,没有困难样本挖掘。
在采用以上策略之后,YOLO v3在等同AP的前提下,速度是SSD系列的3倍以上。
作者在文章开头就说过YOLO v3的改进主要借鉴了其他人的想法,这自然意味着并非所有的想法都是有效的。这些无效的做法如下:
预测anchor的位置偏移
使用线性激活将anchor宽高与缩放因子的乘积当做x、y来预测会造成模型不稳定。
使用线性而非logistic预测x, y
会掉点。
Focal loss
为YOLO v3启用Focal loss会导致mAP降低2个点。作者认为这是由于Focal loss要解决的样本不均衡问题限于分类任务,而YOLO v3会单独预测物体是否存在,以及以此为条件的分类。
双IoU阈值
Faster R-CNN中使用上限阈值与下限阈值来区分正负样本,中间的忽略。这对YOLO v3无效。
这些有什么意义?
这个问题不是我提出来的,而是YOLO v3的作者。而且我觉得最后一章的内容已经超越了一份技术报告的范畴。为了方便读者我把原文逐字翻译如下:
或许更好的问题应该是:“当拥有了这些优秀的检测器,我们应该拿它们去做什么?”大部分从事此项研究的人都在Google与Facebook。我猜这些技术至少是在正确的人手里,绝不会用做收集你的个人信息然后卖给…等等,你说这是他们正在做的事情??嗷。
那么其它重金投入视觉研究的人是军方,相比他们永远不会做出使用新技术大量X人这样可怕的事情。嗷,等等……
我希望大部分使用计算机视觉的人都在从事令人愉快且善良的事业,例如计量国家公园里的斑马数量,追踪房屋周边的流浪猫。但是计算机视觉已经在备受争议的用途中获得应用,而作为研究人员我们有责任至少考虑一下我们的工作可能造成的伤害,并且想办法减轻它们。我们欠这个世界太多。
最后,不要@我。我已经退出Twitter了。
作者在文末特别注明:作者受到美国海军与Google的资金支持。
微信扫一扫分享



评论 ()