R-CNN进化论
从R-CNN、Fast-R-CNN与Faster-R-CNN的演化看物体检测进化背后的规律

封面图片:Alexander Popov
作为基于深度学习物体检测的开山之作,R-CNN、Fast R-CNN与Faster R-CNN系列是初学者绕不开的坎。6年过去了,当前众多优秀的物体检测方案中仍然能看到他们的影子。所以,如果要掌握基于深度学习物体检测的原理,就请从这一系列开始吧!
R-CNN:神经网络初尝试
R-CNN是由来自UC Berkeley的Ross Girshick等人在2014年发表的文章“Rich feature hierarchies for accurate object detection and semantic segmentation”中提出的一种基于深度学习的物体检测方案。该方案将候选区域(Region Proposals)与卷积神经网络(CNN)联合起来,故得名R-CNN。
2012年AlexNet在图像分类竞赛ImageNet中取得了相较于传统方案的优异成绩。然而在当时的物体检测领域PASCAL VOC挑战中,流行的方案仍然以SIFT、HOG特征为核心。这一现象启发了R-CNN作者,他们在论文中写到
To what extent do the CNN classification results on ImageNet generalize to object detection results on the PASCAL VOC Challenge?
在ImageNet图像分类领域获得优异结果的卷积神经网络,如果用在图像检测领域的PASCAL VOC挑战中,其能力能够泛化到多大程度?
为了回答这一问题,R-CNN给出这样一种设计方案。
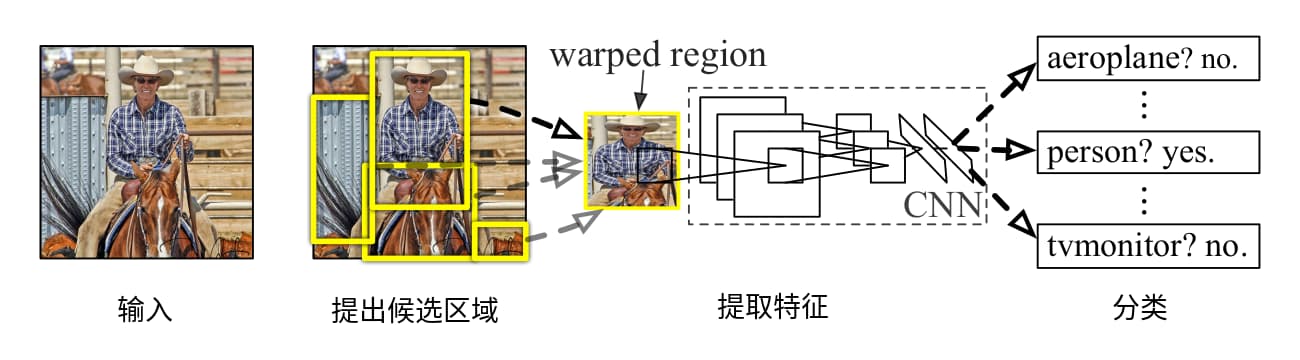
该方案由三个模块组成。第一个模块在不考虑物体类别的前提下从图像中筛选出候选区域。第二个模块是一个大型的卷积神经网络,为第一个模块给出的每个候选区域提取长度为4096的特征向量。第三个模块是一组线性SVM,根据特征向量给出分类结果。如上图所示。
不难看出,神经网络在R-CNN中仅仅工作在第二模块——特征提取。提出候选区域的方法为selective search,而分类则是基于SVM。所以这并非一个端到端的神经网络物体检测方案。
R-CNN在准确率上获得极大的提升,但是其缺点也非常明显:
- 训练不是端到端的,而分了三步。首先精调卷积网络,然后拟合SVM,最后学习边界框回归。
- 训练耗费资源。VGG16网络下,5千张图片训练耗时2.5 GPU日。
- 推演速度慢。GPU下一张图片需47秒。(这里的GPU为NVIDIA K40,超频至875MHz)
尤其是速度,恐怕没有人能够忍受长达47秒的检测时间。究其原因也很直观:对于第一模块给出的每一个候选区域,都需要执行一遍神经网络的前向传播以获取特征。而这些大量的、甚至是重复的前向传播运算有极大的优化空间。
R-CNN并非第一个将神经网络引入到物体检测领域中来的,不过它一定是最知名的一个。并且随着它的两篇续作逐一攻克了它的主要短板,使得R-CNN系列成为神经网络物体检测的经典之作。
SPP-net:我能加速100倍!
R-CNN发表于2014年,同年微软研究院的何恺明等人发表了一篇论文“Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition”。该文提出了SPP-net的概念,并将其用在R-CNN物体检测中,将检测速度最大提升了100倍!
SPP-net的核心在于spatial pyramid pooling layer(SPP-layer)。在步长一定时,CNN中的池化层输出的特征图尺寸取决于输入尺寸。同为池化层,SPP-layer输出是固定的。
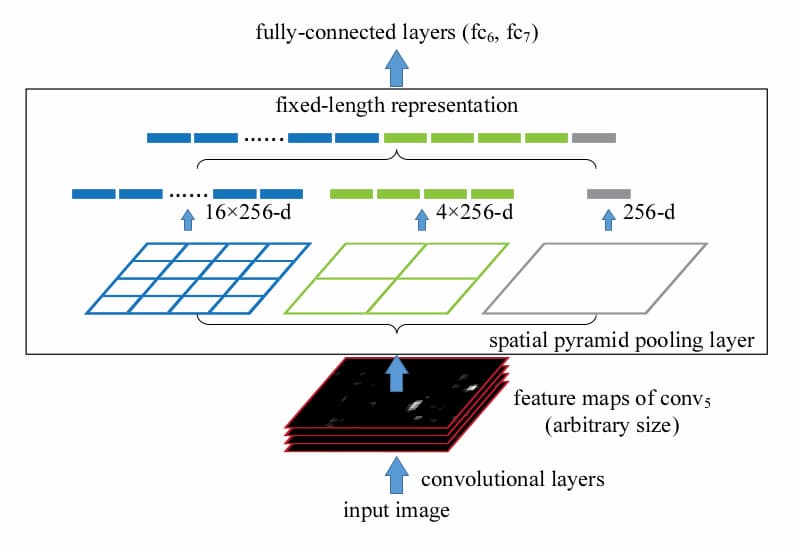
SPP-net的本意是要解放神经网络输入尺寸限制,这一限制通常来自于网络末端的全连接层。但是该文作者使用SPP-net改进R-CNN时,将候选区域的提取操作放在了特征提取的后端,直接从特征图上提取候选区域。于是R-CNN中高达2000多次的前向传播被SPP-net中的一次前向传播替代了,避免了大量的重复计算,获得了数量级的速度提升。
Fast R-CNN:再见SVM
如此巨大的改进不可能不被关注。2015年,R-CNN的第一作者Ross Girshick发表了续作Fast R-CNN。此时的Ross已经是Microsoft Research的成员。这篇文章的标题就叫“Fast R-CNN”,这一简洁的标题显然是受惠于前作R-CNN的知名度。
Fast R-CNN引入SPP-net的思想,并且针对R-CNN额外做了一些改进。
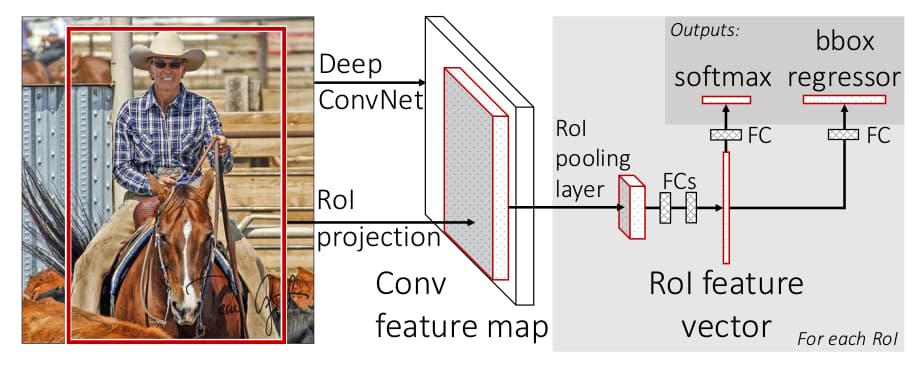
上图展示了Fast R-CNN架构。与R-CNN不同,神经网络将整个图像纳为输入项目并生成特征图,之后针对每一个候选区域做RoI Pooling与全连接层获得特征向量,再使用两个全连接分支分别输出类别与边界框。原来的SVM消失了。
与R-CNN相比,Fast R-CNN最大的改进是速度提升:训练速度是R-CNN的9倍;如果排除提出候选区域的时间,推演一张图片耗时0.3秒;准确率mAP相比RCNN提升了4%。另外,训练过程引入多任务损失函数避免了R-CNN中使用的分阶段训练。整体上看起来更加的“神经网络”。
当然,技术进化的脚步永不会停止。R-CNN最初提出的三大模块中仍然有一个模块未被攻克,成为瓶颈——筛选候选区域。
Faster R-CNN:你好,RPN!
毫无疑问,使用神经网络替换Selectvie Search实现候选区域的筛选功能是最有前景的方向。2015年,以任少卿为第一作者,何恺明为第二作者,Ross Girshick为第三作者的文章“Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”中正式提出了替换Selectvie Search的方案:Region Proposal Network,简称RPN。
作为Faster R-CNN的一个组成部分,RPN以图像作为输入,输出一系列带评分的矩形候选区域。吸取了Fast R-CNN的经验,RPN与后续的特征提取部分共享一部分卷积层。在最后一个共享卷积层的输出特征图上,使用一个深度为256的小型3×3卷积在整张特征图上扫描,其后跟随两个全连接分支分别输出是否有物体存在的评价结果与位置。在每一个滑过的位置上,最多输出k个候选项。这里的候选项有一个如雷贯耳的名字:Anchor。Anchor有着不同的尺寸与形状,以便拟合不同尺度的物体。对于一张尺寸为W×H的特征图最终输出的Anchor数量为W×H×k。在Faster R-CNN中,k等于9。注意RPN生成的候选项是与类别无关的,它仅仅提出“此处可能有物体存在”的建议,而具体是什么类别的物体则交给Fast R-CNN做出判断。这是一种“提案-检测”两步走的方案。
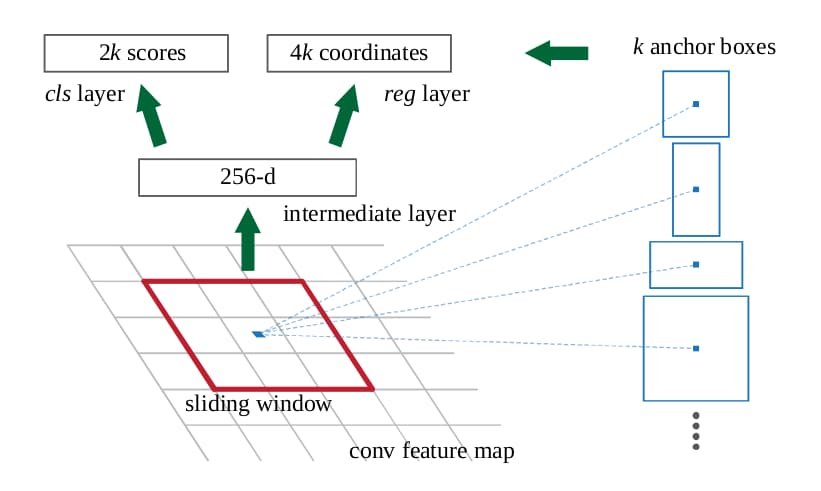
RPN成功取代了Selective Search,并且与Fast R-CNN共享部分神经网络计算。至此,一种以神经网络为核心的物体检测方案基本成型。
R-CNN的演化论
从R-CNN到Fast R-CNN再到Faster R-CNN,神经网络依次实现了物体检测过程中特征提取、分类以及候选区域提议功能,形成了一套成熟的,以神经网络为核心的物体检测方案。在这个过程中,整合与共享神经网络参数,引入多任务训练等方式不仅显著地降低了运算时间(从47秒到0.2秒),还证明神经网络具备强大的表达能力。
不仅如此,Anchor设计,正负样本均衡等训练手段也在持续地启发着后来者。当前一些取得优异成果的物体检测方案中,你仍然能够看到R-CNN的影子。对于初学者来说,R-CNN系列是掌握深度学习物体检测原理的一次绝佳机会。
微信扫一扫分享



评论 ()