基于深度学习的人脸特征点检测-移植到iPhone
如何通过CoreML在iPhone应用中使用TensorFlow模型

在上一篇博文中,我们已经获得了一个可以检测人脸特征点的神经网络模型,并且使用Python语言在PC上进行了测试。在本文中,我将演示如何将训练好的模型移植到iPhone上运行,通过手机摄像头来检测人脸特征点。
iPhone的野心:A11仿生芯片与CoreML
在深度学习大放异彩的今天,Apple也不甘为人后。在2017年发布的iPhone 8/Plus以及被誉为未来的手机iPhone X,都为神经网络的应用做了十足的准备。具体来说,Apple从硬件与软件两个维度做了改进:硬件体现为A11仿生芯片,软件体现为CoreML。
A11仿生芯片
Apple官网是这样介绍A11仿生芯片的:
神经网络引擎:A11 仿生闪亮登场。这款 iPhone 上有史以来最强大、最智能的芯片,拥有一个每秒运算次数最高可达 6000 亿次的神经网络引擎。

这款芯片专门为神经网络进行了定制化的设计,对于我们来说绝对是一个好消息,这意味着在iPhone X上我们的神经网络模型可以跑得更快,且不需要过于担心发热的问题。
CoreML
普通iPhone用户恐怕不熟悉这个名词,不过iOS开发者看名字就知道CoreML和CoreImage等一众兄弟一样,是Apple针对旗下设备提供的软件开发框架[1]。Apple官网是这样介绍CoreML的:
Core ML lets you integrate a broad variety of machine learning model types into your app. In addition to supporting extensive deep learning with over 30 layer types, it also supports standard models such as tree ensembles, SVMs, and generalized linear models. Because it’s built on top of low level technologies like Metal and Accelerate, Core ML seamlessly takes advantage of the CPU and GPU to provide maximum performance and efficiency. You can run machine learning models on the device so data doesn't need to leave the device to be analyzed.

从描述来看,CoreML支持超过30层的神经网络推演,我们训练的这个10层网络模型对它来说小菜一碟。并且从之前WWDC 2017的CoreML发布会上来看,CoreML的使用是相当的简单[2]。
转换TensorFlow模型到CoreML
Apple与Google都有自有品牌的手机在市面销售,不过在深度学习方面,Apple则缺乏类似TensorFlow这样的神经网络框架可以用。好在Apple专门提供了一款工具可以将训练好的TensorFlow网络模型导出为CoreML支持的格式。这款工具就是tf-coreml,开源在Github上[3]。
提示:你可以通过pip来安装tf-coreml,且需要Python2环境。
tf-coreml附带了一些示例jupyter notebook文件在example目录下[4]。其中 inception_v1_preprocessing_steps.ipynb 演示了转换模型的整个过程,按照notebook中的提示照做即可,不过需要注意以下两点:
input_name_shape_dict是用来指定输入的Tensor维度,如果是单个样本,在TensorFlow中导出pb文件的时候需要指定输入tensor的第一个维度为1。否则在转换时会报reshape相关的错误。- 如果输入为图像,建议不要省略
image_input_names参数。这样生成的模型在Xcode中会识别出输入变量为image类型,否则将会被识别为MLMultiArray类型,需要自行转换变量类型。
基本上注意这两点就没啥问题,剩下的事情tf-coreml会帮你处理好,最终生成一份扩展名为.mlmodel的文件。这个文件就可以在Xcode中直接使用了。
![]()
在Xcode中使用CoreML
从摄像头视频流中抓取画面
虽然Apple官方提供了好几个摄像头相关的示例代码,但是从源码上看他们的重点在于如何使用高阶的API去控制摄像头的使用,瞄准的是基于拍照的应用。且代码量也非常庞大。在这里我推荐一个简单小巧的FrameExtractor,它用尽可能少的代码实现了帧画面的提取功能,对于我们简单验证来说足够了[5]。
使用Vision框架
尽管我们可以直接使用CoreML来操纵导入的模型,但是从易用性的角度考虑,我建议使用Vision框架来实现图像相关的应用。
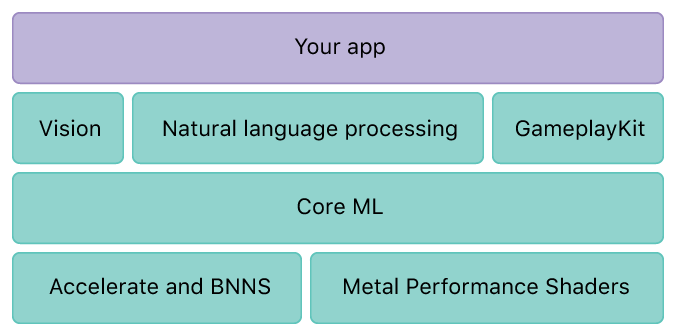
Vision建立在CoreML基础之上,借助它可以快速的实现人脸识别,特征检测,场景分类等计算机视觉类应用。同样,Apple官方提供了一份示例代码可以参考[6]。
从示例来看,基于Vision来使用自定义的神经网络模型分三步。
第一步:生成请求
直接将mlmodel文件拖入到Xcode中,Xcode会自动解析模型文件如下:
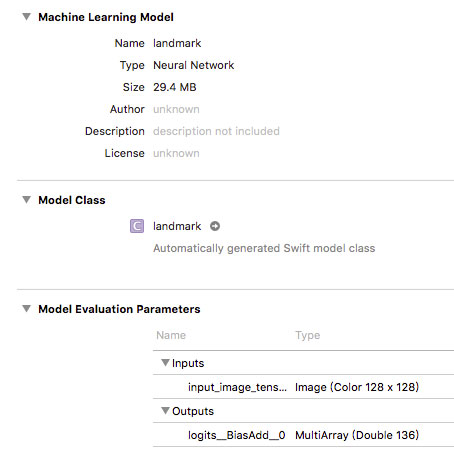
其中可以清晰的看到,模型的输入为 image (color 128 x 128),输出为MultiArray 136,即68个特征点的坐标。模型导入后需要用以下代码将其实例化并生成请求:
// 模型实例化
let model = try VNCoreMLModel(for: landmark().model)
// 生成请求
let request = VNCoreMLRequest(model: model, completionHandler: { [weak self] request, error in self?.processLandmarks(for: request, error: error)
})
第二步:执行请求
我将检测特征点的代码放在了拿到每一帧画面后:
let handler = VNImageRequestHandler(ciImage: ciImage, orientation: orientation!)
do {
try handler.perform([self.landmarkRequest])
} catch {
print("Failed to perform landmarks.\n\(error.localizedDescription)")
}
第三步:处理检测结果
由于我们的模型输出的是68个特征点的坐标,因此这里需要将返回值解析为VNCoreMLFeatureValueObservation,这样可以得到一个1x136大小的MLMultiArray,之后再手动从中提取坐标即可。
guard let observations = request.results as? [VNCoreMLFeatureValueObservation]
else { fatalError("unexpected result type from VNCoreMLRequest") }
guard let faceMarks = observations.first?.featureValue.multiArrayValue
else { fatalError("can't get best result") }
self.marks = faceMarks
以上三步基本上就是官方文档里介绍的内容,只是我们的模型不是分类模型而已,因此有一些微小的变化。全部完成之后,就可以在iPhone中运行了。截图如下:
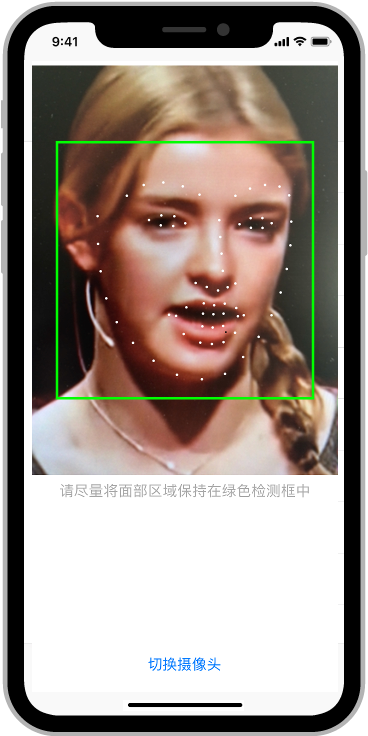
经过我的实际测试,在iPhone X上可以做到摄像头画面的实时检测,没有发现明显迟滞。
小结与下一步计划
我们已经将面部特征点检测模型移植到了iPhone上,但是由于与之配套的人脸检测模块并没有一同移植过来,因此需要手动将面部区域置于检测框中,导致最终的检测结果受到检测框的很大影响,这一点在之前的文章中已经有讨论过[7]:。
经过实际验证,当前的网络模型在iPhone X上可以做到实时检测,这得益于当前移动设备日益强大的计算能力,尤其是专门针对神经网络做过优化的设备。除了iPhone X,基于高通835系列的手机以及华为P10等提供了神经网络加速的设备,猜测有着相似的效能。
最后,这个系列的文章展示了如何从零开始,完成数据搜集、整理,神经网络模型建立、训练、测试、部署到手机的完整过程。下一篇博客将是这个系列的最终篇,我将分享整个过程中自己的一些心得体会,非技术内容,敬请期待!
本文涉及到的代码开源在Github上,地址如下:
https://github.com/yinguobing/face-marks


Comments ()