基于深度学习的人脸特征点检测-模型导出与应用
使用Estimator API时,导出适用于推演的网络模型的正确方法。

在上一篇博客中,我们通过训练最终获得了一个可以输出人脸特征点坐标的神经网络模型,并且使用基于TFRecord格式的测试数据集大致验证了训练结果。在实际的使用环境中,需要检测的数据可能是图像或者视频,且检测有可能是实时的。将待检图片首先转换为TFRecord格式是不可行的,需要一个方便推演的方法。在本文中,我将简单介绍基于TensorFlow Estimator的网络模型导出方法,并演示如何利用Python将导出的网络模型应用在实际视频中。
TensorFlow如何保存模型
当使用Estimator时,TensorFlow会自动将运算图以及其中相关的变量保存下来。如果按照使用目的来划分的话大致分为以下几种:
- 主要用于保存与恢复训练进展的checkpoint
- 主要用于推演的.pb文件
其中checkpoint不仅仅包含了用于推演的网络,还包括用于训练的网络。由于Estimator自动帮助我们管理训练进度的保存与恢复,因此checkpoint是它的默认存储方式。如果训练完成,希望进行部署的话,我们需要手动将适用于推演的网络部分另行导出。
使用Estimator保存模型
TensorFlow官方推荐使用SavedModel的形式来保存模型,并提供了一份基于Estimator的教程[1]。按照说明,保存模型需要在Estimator的基础上完成:
- 定义一个用于推演的输入函数
- 定义用于输出类型与名字
其中用于推演的输入是需要留意一下,在构建网络时为了方便批量运算,网络模型的输入shape为[?, 128, 128, 3],在推演阶段我们一次只会送入一个样本,这意味着第一个维度的尺寸将固定为1。因此输入函数需要将输入的单张图片维度进行扩充。
至于输出类型,如果不是用在TensorFlow serving,则需要输出类型定义为一般类型tf.estimator.export.PredictOutput。
完成以上两点,即可通过以下函数导出模型为SavedModel。
estimator.export_savedmodel(export_dir_base, serving_input_receiver_fn)
在导出之前,一份checkpoint包含三个文件,后缀名分别为data、index和meta,总大小在88MB左右。在存储为SavedModel后,用来存储网络的文件同样是三个如下:
- saved_model.pb,protobuf格式文件,70KB。
- variables.data文件,29.4MB。
- variables.index文件,1KB。
按照官方的说明,SavedModel已经可以用在具体的推演过程中了。不过三个分离的文件看上去总是有点别扭,如果你也这么想,那么接着往下看。
导出主要用于推演的.pb文件
实际上,TensorFlow的确还提供了一种网络的保存形式,专门用于推演使用,且只有一个pb文件。这种形式在官方的示例代码里被大量的使用。而且官方也提供了这么一样工具用来将网络“冻结”为推演专用,它就藏在freeze_graph.py这个文件中[2]。
该文件的使用并不复杂,仔细看注释即可。这里提醒一下,由于我们已经将模型导出为SavedModel的形式,因此在使用时可以使用参数--input_saved_model_dir直接指定模型所在的文件夹。
完成以上步骤,最终获得一份独立的pb文件,大小为29.4MB。这个文件中包含了用于推演的网络结构与变量的数值。如果你还不满意,可以留意一下该目录下的optimize_for_inference.py文件,它可以进一步精简pb文件。你也可以尝试一下,不过我精简过后文件的尺寸没有明显的变化。
以上内容并不复杂,只要认真阅读文档不难做到。如果你遇到困难也可以参考我在Github上的开源实现[3]。
使用Python读取模型
一旦模型保存完毕,就可以将该pb文件用于后续的推演操作。在Python中读取并激活网络也是非常简单,几行代码即可:
# Load a (frozen) Tensorflow model into memory.
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
sess = tf.Session(graph=detection_graph)
后续的使用就非常简单了,我提供了一份基于OpenCV的示例代码,演示了如何从视频文件中检测人脸并提取特征点[4]。
同时还与当前流行的dlib开源库的效果做了对比。如果你感兴趣可以参考开源代码[5]。完整的视频在这里:youtube
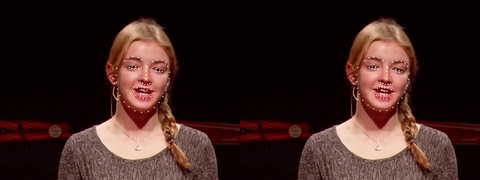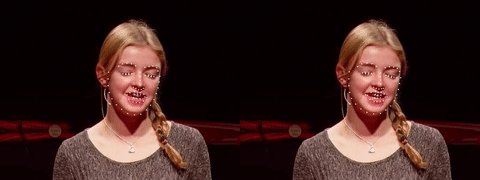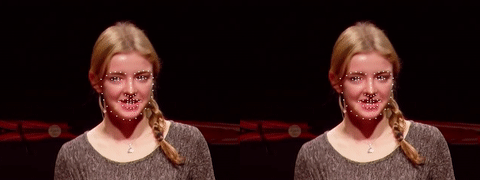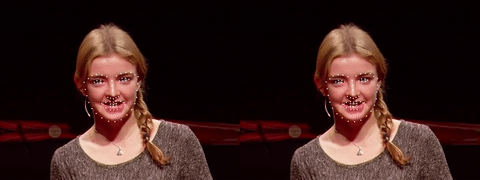


https://tensorflow.google.cn/programmers_guide/saved_model#using_savedmodel_with_estimators ↩︎
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/tools/freeze_graph.py ↩︎
https://github.com/yinguobing/cnn-facial-landmark/blob/save_model/landmark.py ↩︎
https://github.com/yinguobing/cnn-facial-landmark/blob/save_model/landmark_video.py ↩︎
https://github.com/yinguobing/cnn-facial-landmark/blob/dlib/landmark_video.py ↩︎
微信扫一扫分享



评论 ()