基于Transformer的物体检测
Attention, attention, attention!

封面图像: Aditya Vyas
End-to-End Object Detection with Transformers 是由Facebook AI的Nicolas Carion等人在2020年发表的文章。文中描述了一种基于Transformer的端到端物体检测方案。你可以在这里找到全文:
官方也释出了基于PyTorch的源码:
 facebookresearch
facebookresearch本文为学习笔记。
物体检测最终要输出的是一系列物体的边界框以及类别标签。RCNN、YOLO、SSD以及其各种变体首先将这个问题转化为针对可能物体区域(propose/anchors)的回归与分类问题。作者认为这种间接的方式是低效的,如NMS以及anchor匹配会对性能造成极大影响。
为了解决这一问题,作者将物体检测任务看作为一种“直接输出预测集”任务,同时采用了序列任务中Transformer的encoder-decoder架构。Transormer中的自注意力机制显式地考虑了序列中元素与元素之间的关系,使得它们特别适合处理集合预测中的去重工作。
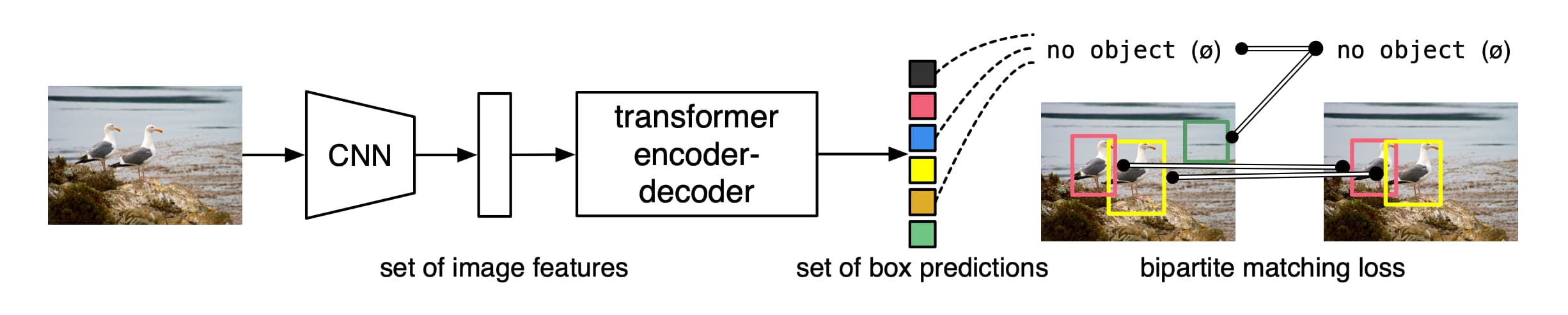
物体检测Transformer(作者简称其为DETR)直接一次性输出全部检测结果,没有anchor,没有NMS。它在训练时使用集合损失函数来实现预测结果与标签数据的双边匹配。在具体实现上只要有标准CNN与Transformer类即可。
与之前的类似工作相比,DETR的主要特征在于将双边匹配损失与非自回归的并行解码Transformer结合起来。匹配损失函数将预测结果与标签单独匹配,并且不受输出结果排列组合的影响,因此可以并行输出。
最终DETR在COCO数据集的表现上接近Faster-RCNN。准确的说,在大物体检测上有所超越,但是在小物体检测上仍有欠缺。
集合预测
此前深度学习模型直接预测集合并无先例。用于可变分类任务中的集合预测一对多的策略不适合检测任务。这类任务的首要难点在于避免相似的重复。常规做法是使用NMS,但是直接的集合预测并没有后处理,而是通过全局推演来模拟所有预测对象的相互作用来避免冗余。对于固定尺寸的集合预测,稠密的全连接网络可行但是耗费巨大。更通用的方法是使用自回归的序列模型如RNN。无论哪种状况,损失函数都应当不受预测结果排列组合的影响。常见的解决方案是基于Hungarian algorithm来设计损失函数,以获得预测值与标签值之间的双边匹配关系。这不仅达成了排列组合不变性,还使得每个目标对象都有独一的匹配结果。与其它工作不同之处在于,作者没有使用自回归模型,而采用了并行解码的Transformer。
Transformer与并行解码
Transformer是由Vaswani等人为机器翻译提出的一种基于注意力的基础结构。注意力机制使得神经网络层可以从整个输入序列提取信息。Transformer引入了自注意力机制,逐个扫描序列中的元素并通过提取完整序列的信息来更新它们。基于注意力的模型最大的优势在于全局计算能力与记忆力,这使得它们比RNN更能适应长序列数据。
Transformer最早用在自回归模型,然而其较高的推演消耗则与输出长度正相关,这又催生了并行的序列生成。这篇文章中作者结合了Transformer与并行解码来获得均衡表现。
物体检测
无论是两步物体检测还是单步检测,它们都依赖某种程度上的初始假设(proposals/anchor)。DETR则不需要这种假设。
基于集合的loss。一些较早使用双边匹配损失的物体检测器中,预测结果之间通过卷积或者全连接层来联系,并且使用手工设计的NMS来改善表现。一些近期的检测器则以非唯一的方式匹配预测值与标签,并搭配NMS。可学习的NMS与关系网络通过注意力显式地联系起了不同的预测结果。使用直接集合损失函数后它们不需要任何后处理。然而这些方法引入了额外手工设计的环境特征。
循环检测器(Recurrent detectors)。一些同样采用双边匹配损失、encoder-decoder以及CNN来直接输出集合结果的类似方案则大多采用了RNN。这导致它们无法充分利用最新的并行解码Transformer。
DETR的精华之处在于:迫使预测结果与标签之间唯一匹配的集合损失函数,以及通过单次前向传播预测物体集合与关系的架构。
集合损失函数
DETR的输出为包含N个预测结果、固定大小的集合,其中N远远大于图像中可能出现的物体数量。假设y为标签、y'为预测结果,将y补全到尺寸N,使用函数L(y, y')代表匹配损失,则存在某种排列组合可以使得匹配损失最小。这种组合可以使用Hungarian algorithm来计算。这里的匹配损失包含了两部分:分类损失与坐标差异损失。这种匹配操作与Proposal/anchor的匹配操作类似。区别在于这里要实现一对一的匹配,而anchor则以IoU阈值作为判别依据。
接下来要计算的则是损失函数。与以前的检测方案类似,当最佳匹配组合获得之后,使用-log分类概率与box loss相加获得。实际中,对于无物体匹配的空集合降10倍权重以解决分类样本不均衡的问题。
Bounding box loss。过往检测方案中,box的预测是相对于anchor而言的。而在DETR直接输出box位置与大小。此时如果使用L1 loss的话,大尺寸物体与小尺寸物体在loss上会面临着较大的尺度差异。作者的解决方案是使用L1与IoU loss的组合方案。
DETR架构
DETR的架构分为三个部分。用于提取特征的CNN,编解码Transformer与前向传播网络FFN(Feed forward network)。
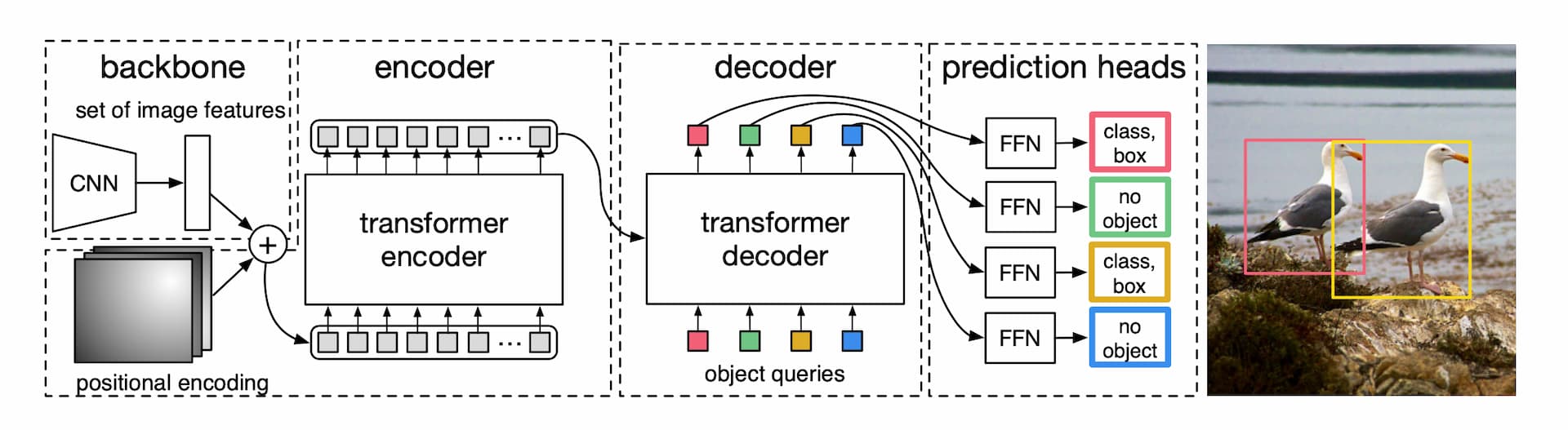
骨干网络。网络输入为3通道的图像,大小W*H。输出尺寸为W/32,H/32,通道数2048。
Transformer encoder。首先使用1x1卷积降低通道数,然后将二维特征图转换为序列以便输入到encoder。Encoder的每一层包含一个多头自注意力模组与一个前向传播网络FFN。作者认为Transformer是permutation-invariant,所以为每个注意力层添加了固定的positional encodings。
Transformer decoder。Decoder需要使用多头自编解码注意力机制对N个尺寸为d的嵌入(embeddings)做出变换。Decoder同样是 permutation-invariant,所以N个嵌入必须是不同的。这N个嵌入是习得的位置嵌入,被称为object queries。Decoder将这个N个queries转换为输出嵌入,然后通过FFN分别解码为边界框与类别标签。
Prediction feed-forward networks (FFNs)。FFN是一个三层感知机,使用ReLU激活函数,输出边界框归一化后的中心位置与宽高。同时还有一个线性投射层,用来输出分类。
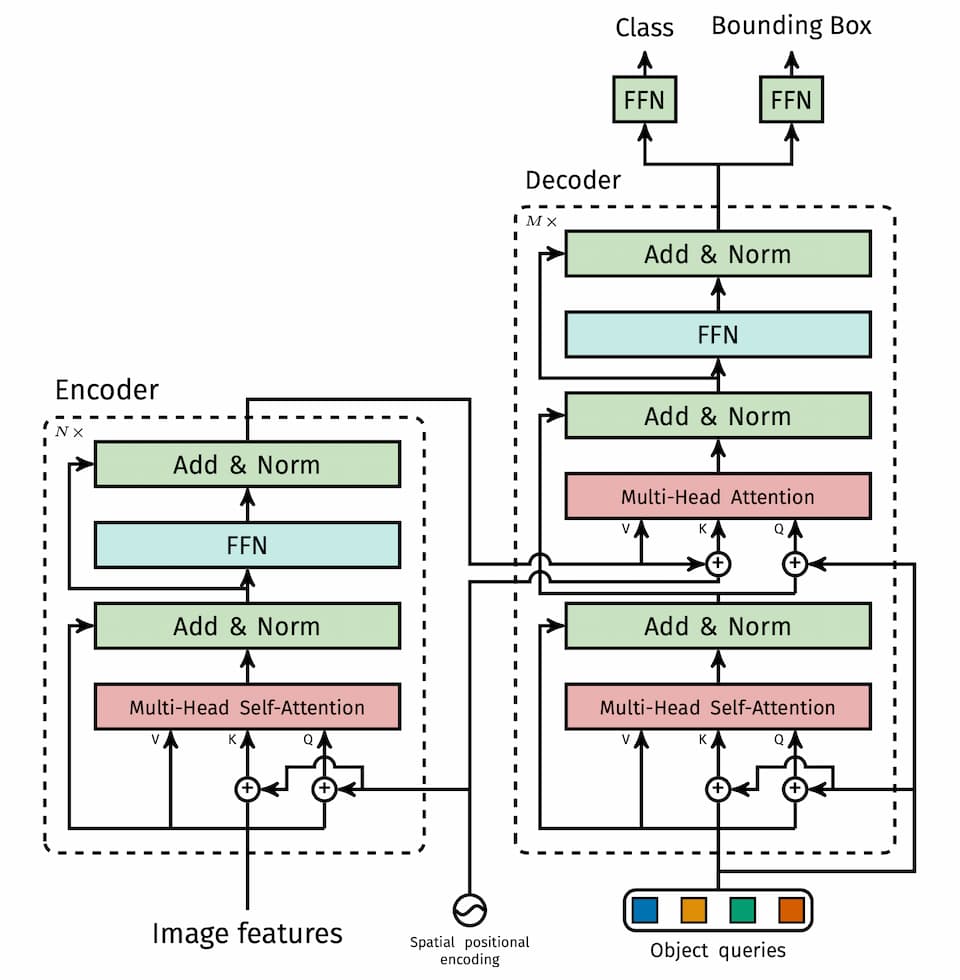
辅助解码损失。作者还发现在decoder中使用辅助损失函数可以帮助模型输出正确的物体数量。每个decoder layer后跟随FFN,这些FFN共享参数。输入到FFN的数据还要经过layer norm层归一化。
以上内容对于了解基于Transformer的物体检测架构应该足够了。原文的后续还有大量的实验设计与分析,限于篇幅这里不再列出。对于我来说,这种方案还有很多不理解的地方。最后一张图里的Encoder-decoder Transformer看上去比传统CNN要复杂很多。尤其是Self-attention,需要仔细研究。
微信扫一扫分享



评论 ()