SSD如何一次成型
Single stage物体检测代表作

封面图片:Markus Spiske on Unsplash
SSD是由Wei Liu等人在2016年发表的文章“SSD: Single Shot MultiBox Detector”中提出的单步物体检测器。其设计理念至今仍活跃在物体检测设计实践中,例如我们之前介绍过Google的BlazeFace。
SSD的关键特征
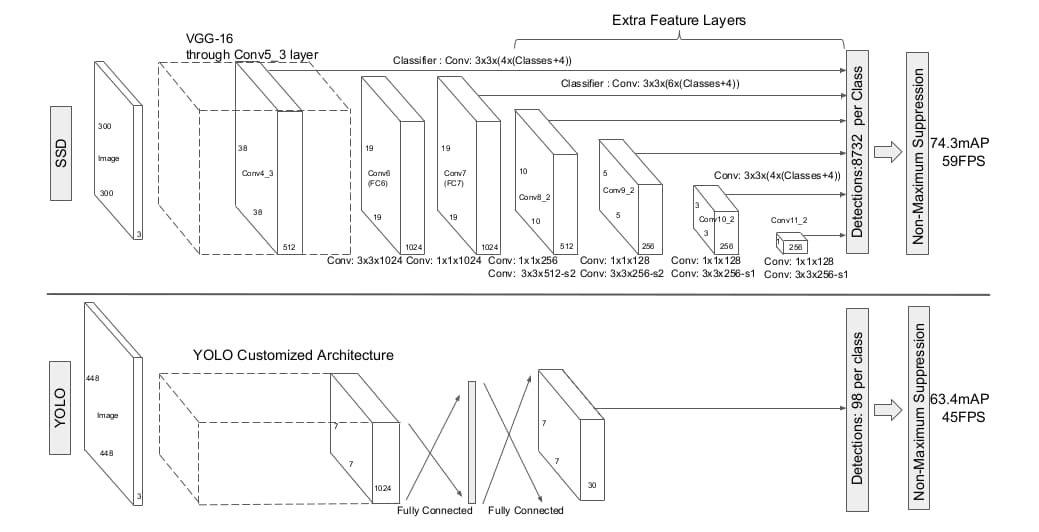
多尺度特征图。模型构建于用于分类的卷积神经网络之上,在其后附加额外的卷积层、渐进式的缩小空间尺度,实现多尺度物体检测。YOLO仅仅使用最后单一尺寸特征图。
使用小尺寸卷积核输出结果。在特征图之上使用3×3卷积输出检测所需的分值与类别,或者anchor对应的偏移。在YOLO中这是通过全连接层实现的。
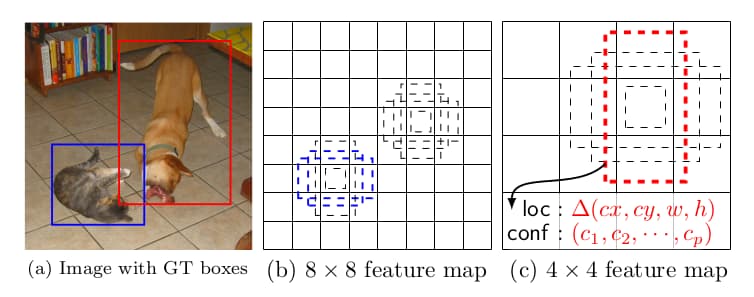
不同规格的Anchor box。针对特征图的每个像素设立anchor box,然后预测边界框相对anchor box的偏移与物体类别。Anchor box的设立是基于不同尺寸特征图之上,所以有利于多尺度物体检测。
训练方式
与需要提出候选区域的两步方案相比,SSD最大的区别在于需要将实际物体信息与模型输出实施匹配。
匹配规则。选择叠加区域最大的目标作为匹配对象,且设置单一阈值0.5。这样可以促使网络为高度叠加的多个anchor输出高分值,而非迫使其选择最大的一项。
训练目标。若使$x^p_{ij}={1, 0}代表第$i$个anchor与第$j$个实际标签在分类$p$上获得匹配,则可以将总体loss函数记为:
$$L(x,c,l,g)=\frac{1}{N}(L(L_{conf}(x,c)+\alpha L_{loc}(x,l,g))$$
其中N为获得匹配的anchor box数量。如果N为0, 则loss为0。定位loss为平滑后的L1 loss。权重$\alpha$等于1。
制定Anchor规格。假设用于检测的特征图数量为m,则用于每个特征图的anchor尺寸可以用如下公式计算:
$$s_k = s_{min}+\frac{s_{max}-s_{min}}{m-1}(k-1), k\in [1, m]$$
其中$s_{min}$为0.2,$s_{max}$为0.9。这意味着最低层特征图anchor尺度为0.2,最高层特征图为0.9,其它均匀分布在中间层。Anchor的比例则取自集合{1, 2, 3, 1/2, 1/3}。当比例为1时,额外增加一个尺度$s'_k=\sqrt{s_ks_{k+1}}$。最终为特征图的每个位置生成6个anchor box。
困难样本挖掘。经过匹配之后的anchor box呈现出极度的不平衡状态——负样本数量远远大于正样本。所以将anchor box按照loss排序并取头部项,保持正负样本比例为1:3。
数据增强。切片,使得重叠区域比例为0.1, 0.3, 0.3, 0.5, 0.7或者0.9,宽高比介于0.2与2之间。切片之后缩放至固定尺寸、水平随机翻转,以及其它一些常规增强操作。
骨干网络。网络基于VGG16改装。将fc6与fc7替换为卷积层。将pool5的2×2-s2替换为3×3-s1。去除dropout与fc8。训练使用SGD,初始学习率10-3 ,0.9 momentum, 0.005的weight decay,batch size为32。
实验分析
经过这一番改造与实验,作者发现如下规律。
数据增强很关键。SSD的数据增强很强势,带来8.8%的mAP提升。
更多样的Anchor有好处。如果去除一部分anchor形状会导致精度损失。
空洞卷积更快。提速约25%。
多分辨率输出更好。在不同尺寸的特征图上使用不同尺寸的anchor,这是SSD的主要贡献之一。
数据增强有助于小尺寸物体检测。SSD采用非常激进的切片策略。这种先大幅度切割后放大至固定尺寸的操作间接提供了小尺寸样本的大尺寸“快照”,有助于网络学习小尺寸样本特征。
总结
SSD的设计思路与RPN很像,区别在于它给出的不是候选区域,而是anchor box的定位与分类结果。SSD与YOLO也很像,区别在于定位运算涉及到了多张不同尺度的特征图,而YOLO只用了一张;以及SSD使用卷积层而YOLO使用全连接层输出结果。
无论结果如何,这些网络的设计都极大的影响了后来者,扩充了物体检测领域的研究思路,为更多样、强大的物体检测框架做出了巨大贡献。
微信扫一扫分享



评论 ()