读懂ShuffleNet V2
高效网络设计的四条指南

封面图片:Daniel Rykhev on Unsplash
本文是对文章“ShuffleNet V2: Practical Guidelines for Efficient
CNN Architecture Design”核心内容的摘抄。作者为来自旷视科技Ningning Ma等。文章的中心内容在于如何设计更加“高效”的网络。你可以在这里找到原文:
深度卷积神经网络的架构创新显著的提升了在ImageNet数据集上的分类准确率,如VGG、GoogleNet、ResNet、DenseNet、ResNeXt、SE-Net以及自动网络架构搜索获得的方案。然而除了准确率,计算复杂度是另一个重要的考虑因素。真实场景应用更加关注在给定运算平台的前提下,如何利用限的资源获得最佳的准确率。这种思路催生了一系列轻量级的架构设计如Xception、MobileNet、ShuffleNet与CondenseNet。在这类网络中,group convolution与depth-wise convolution起着重要的作用。
浮点数运算量FLOPs被广泛用作计算复杂度的评估指标。然而,FLOPs是一项间接指标,无法与直接指标如速度和准确率等同。过往的工作也证明FLOPs相同的网络运算速度却不同。单一使用FLOPs作为评估指标可能导致次优方案。
直接指标与间接指标的矛盾可以归咎于两点原因。第一,FLOPs没有考虑影响速度的一些重要因素。例如内存访问成本,它在group convolution中占据大量运算时间,也是GPU运算时的潜在性能瓶颈;还有并行度。相同FLOPs的情况下,高度并行的网络执行起来会更加迅速。
第二,FLOPs相同的操作,在不同平台下运行时不同。例如早期工作广泛使用张量分解来加速矩阵乘法。但是近期工作发现虽然它可以减少75%的FLOPs,但是在GPU上运算却更慢了。作者研究后发现这是因为最新的CUDNN(该文章发表于2018年)针对3×3卷积做了特殊优化。
因此,作者提出了高效网络架构设计的两大原则。第一,使用直接指标(如速度)而非间接指标(如FLOPs);第二,需要在目标平台上验证该指标。同时提出了四条与跨平台的设计指南,并在该指南指导下设计了一款新的网络架构ShuffleNet V2。
设计高效网络的实用指南
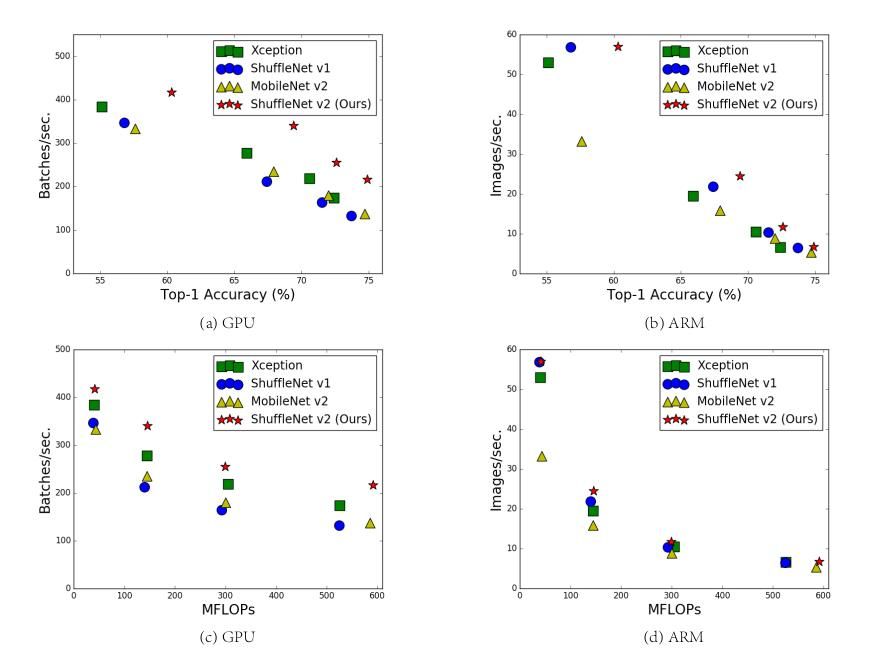
该研究在两类具备工业级优化神经网络库的硬件上开展。作者认为他们的CNN库效率比大部分开源库更高。
- GPU。硬件为英伟达GTX 1080 Ti。软件CUDNN 7.0。
- ARM。硬件为高通Snapdragon 810。软件基于Neon高度优化的实现,测试时单线程。
其它设置还包括:完整的优化选项,开启tensor fusion。输入图像尺寸224×224。所有的网络随机初始化,测试重复100次,取运行时的平均值。测试对象选择了ShuffleNet v1与MobileNet v2,分别代表了group convolution与depth-wise convolution两种流行趋势。
整体运行时被按照操作类别分解如下图所示。FLOPs仅考虑了卷积运算部分,忽略了其它操作如数据I/O、随机化等同样耗时的操作。因此是不准确的。
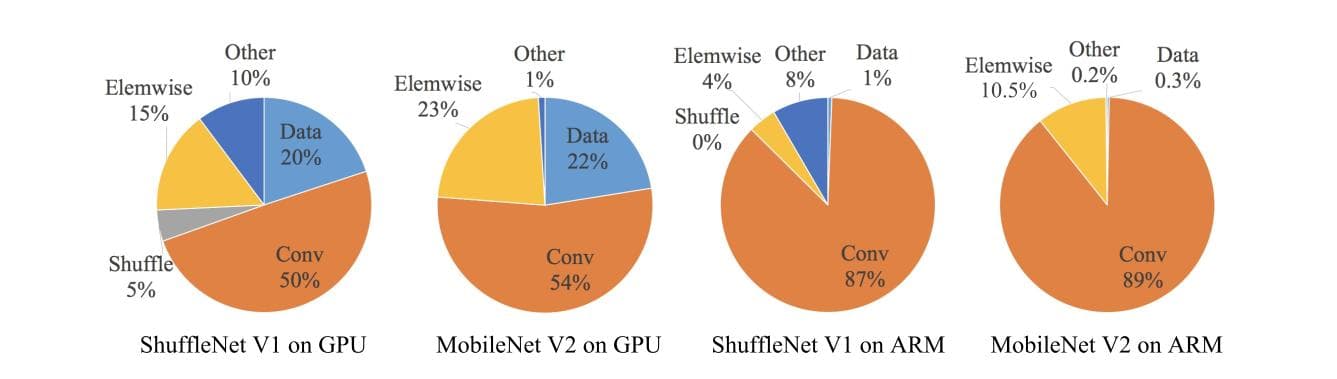
在此基础上,作者针对高效网络设计提出了四条指南。
指南一:保持通道数恒定以最小化内存访问成本
在使用depthwise separable convolutions的网络中,pointwise卷积承担了大部分复杂度。输入通道数c1 与输出通道数c2 决定了网络形状。特征图的高度与宽度为 h 与 w,则1×1卷积的FLOPs为 $B=hwc_1c_2$ 。
假设缓存足够大能够储存下完整的特征图及参数。内存访问成本可以记为 $ MAC=hw(c_1+c_2)+c_1c_2$。根据均值不等式可得:
$$ MAC >= 2\sqrt{hwB} + \frac{B}{hw} $$
可见MAC的下界由FLOPs决定。当输入与输出通道相等时值最小。
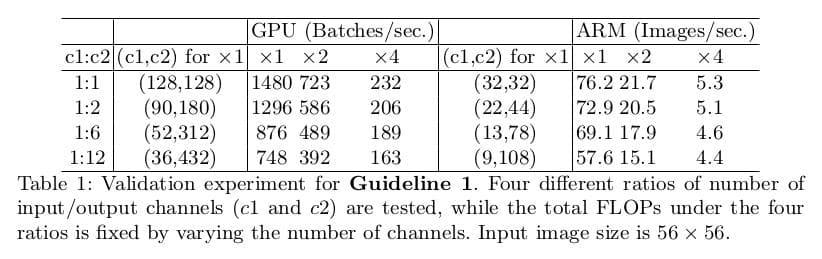
这个结论是理论上的。实际的设备缓存通常不够大。现代运算库通常使用复杂的阻挡策略来最大化缓存的使用。为验证该指南,作者在测试网络中堆叠了10个block,每个block包含2个卷积层。第一个输入通道c1,输出通道c2,;第二个则反过来。实验结果如下表,当c1:c2接近1:1时,MAC最小。
指南二:避免过度的分组卷积
分组卷积将稠密的卷积连接离散化,降低了FLOPs,使得使用更多的卷积通道成为可能。但是,这种操作增加了内存访问成本。
同指南一,1×1卷积的MAC公式可以记为:
$$ MAC=hw(c_1+c_2)+\frac{c_1c_2}{g}=hwc_1 + \frac{Bg}{c_1} + \frac{B}{hw} $$
其中$g$为分组的数量,$B=hwc_1c_2/g$为FLOPs。可见,当$g$增大时,MAC增大。
作者的实验显示,相比标准卷积,分组数为8的卷积运算耗时在GPU上增加了一倍,在ARM上增加了30%。因此分组卷积带来的准确率上升是以速度为代价的,需要谨慎设计。

指南三:谨慎使用碎片化的网络
碎片化运算使用多个较小的运算取代单个较大的运算。尽管这样可以提升准确率,但是却降低了网络的并行度。这尤其不利于强并行运算资源如GPU,还会带来额外的kernel载入与同步损耗。
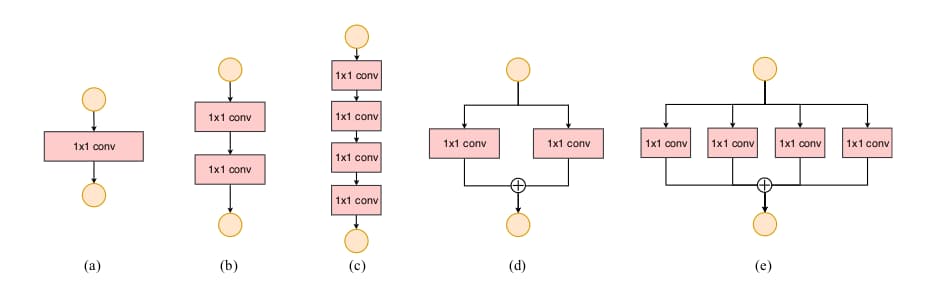
为了量化碎片化带来的影响,作者设计了上图所示block。实验中,GPU下采用图c的网络比采用图a的慢3倍。在ARM下的影响则有限。
指南四:不可忽视逐元素操作的负面影响
逐元素操作包括ReLu、AddTensor、AddBias等。他们的FLOPs相对较小,但是内存访问成本却很高。(作者将depthwise convolution也看做逐元素操作)。试验中,去除ReLU与shortcut连接的ResNet在GPU和ARM上的速度都提升了20%。
小结与讨论
综上,作者认为高效的网络设计应当:
- 使用均衡的卷积策略(通道数恒定)
- 警惕群组卷积
- 减弱碎片化程度
- 减少逐元素操作
ShuffleNet V2: 一种高效架构
ShuffleNet V1使用了pointwise group convolution以及类bottleneck结构,还引入了channel shuffle操作来促进不同群组间的信息交换。从上述的四个指南出发,作者提出了改进的ShuffleNet V2。
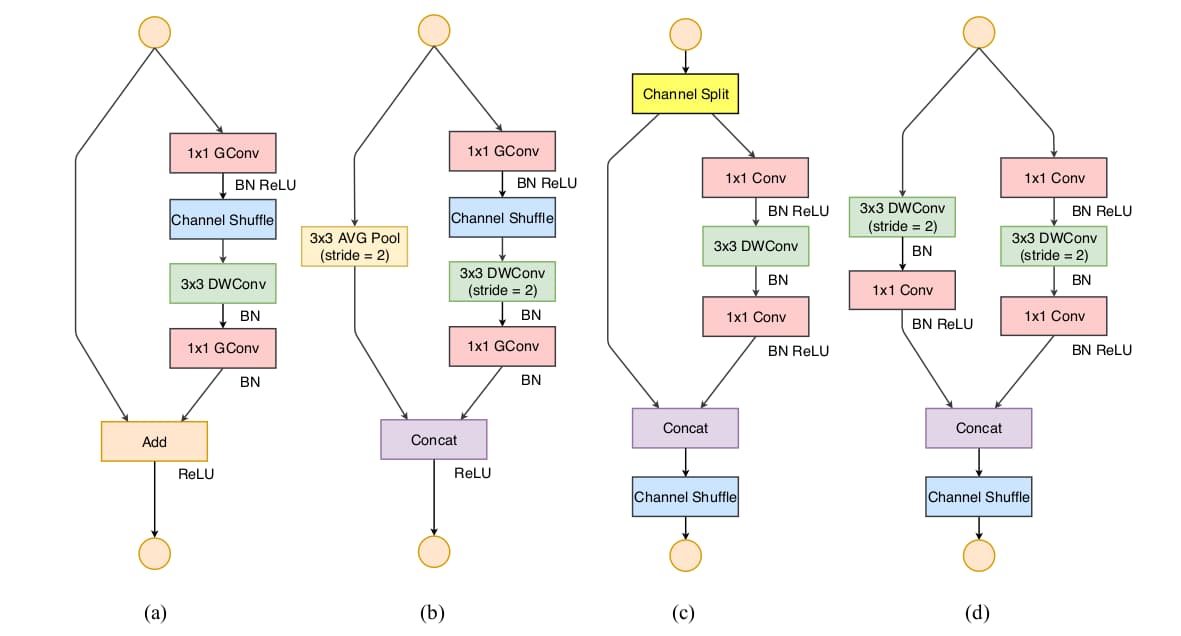
通道切分
作者设计了通道切分(channel split)操作如上图(c)所示。在每个单元前输入通道c被划分为c-c'与c'两个分支。为避免碎片化,一个分支保持不变;另一个分支遵循指南一,包含3个恒等通道数的卷积层,且1×1卷积不再分组。之后两个分支拼接为一个,通道数不变;再执行通道随机化操作。对于具备降采样功能的单元如图(d)所示,去掉了通道切分后,输出通道数扩增一倍。
ShuffleNet V2就是基于以上两种单元构建的。为了简化操作,模型的c'=c/2。网络整体架构类似ShuffleNet V1,具体参数如下表所示。有一点不同之处是在global averaged pooling前增加了1×1卷积以融合特征。每个单元的channel数是可变的,以便统一缩放改变网络的复杂度。
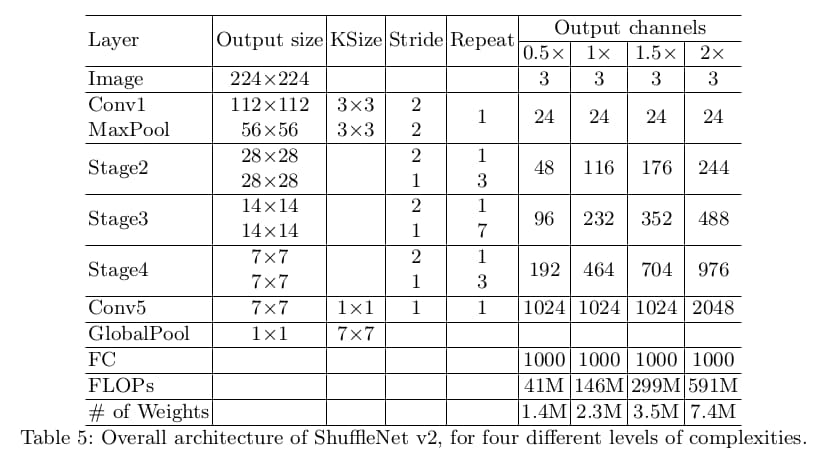
准确率分析
ShuffleNet不仅高效,同时还很准确。原因在于:第一,提效后网络可以使用更多的通道数。第二,每个单元内一半的通道直接馈入下一个单元。这可以看作是某种程度的特征再利用,类似DenseNet与CondenseNet。
结论
ShuffleNet的作者认为运算速度等直接指标应当是神经网络模型设计的一个重要因素。以此为前提作者分析了常用的网络设计策略对内存访问成本的影响,提出了四个高效网络设计指南,并设计了一种新的神经网络架构。
相比之前的网络设计以准确率为主要诉求,该文章提出的观点在设计网络时提供了更加全面的视角,值得关注。
微信扫一扫分享


评论 ()