深度学习要买RTX3080吗
老黄又来割你韭菜了?

记得吗,两年前我们讨论过2080呢!
RTX 30系列显卡发布了。老黄又从自家烤箱里端出了新鲜出炉的RTX 30系列显卡——一共三个型号:RTX 3090、RTX 3080和RTX 3070。没有看的小伙伴可以去B站看官方视频回放,时长40分钟:
 NVIDIA英伟达官方账号
NVIDIA英伟达官方账号
RTX 30系列采用的全新架构Ampere得名于著名法国物理学家安培。官方宣称该系列的性能提升“是上一代产品图灵架构的2倍”。不过对于深度学习从业者来说,最关心的部分其实是GPU核心中的一块特殊区域:Tensor Core(张量核心)。
Tensor Core数量之谜
2018年我们在文章“深度学习要买RTX 2080吗?”分析过,RTX系列显卡对于深度学习来说最大的优势在于专为神经网络设计的运算单元——Tensor Core(张量核心)。这一在Volta架构中第一次引入的硬件设计可以有效的提升神经网络的运算速度,缩短网络训练时间。不过目前为止,我还没有找到RTX 30系列Tensor Core参数的准确数据。
RTX 30系列采用了全新的Ampere(安培)架构。在《英伟达安培架构白皮书》中明确的记录了用于数据中心的 NVIDIA A100的单块GPU中配备了432个Tensor Core,这一数量比Vlota架构的640个要少。但是白皮书中表明Ampere架构下4个Tensor Core在运算力上是上一代架构8个Tensor Core的2倍,相当于4倍性能提升。如果按此标准换算的话,安培架构的单块GPU相当与具备了2560个Tensor Core。RTX系列是家用产品,虽然同样采用Ampere架构,但是规格一定会缩水。目前我在Tom's Hardware网站上找到RTX 30系列关于Tensor Core个数的数据如下表:
| 型号 | 张量核心数量 |
|---|---|
| RTX 3090 | 328 |
| RTX 3080 | 272 |
| RTX 3070 | 368 |
这个数据非常诡异,最低端的RTX 3070居然拥有最多的Tensor Core。考虑到官方没有公布具体参数,我对该数据持怀疑态度。
性能有提升,但别忘了看小字
虽然Tensor Core数量不明,不过官方给出了一些实际运算的性能对比。这里摘抄2项关键指标:
| 参数 | V100 | A100 |
|---|---|---|
| Peak FP16 Tensor TFLOPS with FP32 Accumulate | 125 | 312/624 |
| Peak FP32 TFLOPS 1 (non-Tensor) | 15.7 | 19.5 |
第一项指标对于神经网络来说参考的价值更大一些。在Tensor Core数量更少的情况下,运算速度翻了一倍多。注意这里有两个数据,后边那个几乎翻了5倍的数据是因为三代Tensor Core引入了一项新功能:稀疏矩阵运算加速。神经网络的底层运算是大规模的矩阵乘法。当矩阵中存在大量的0值时,该矩阵为稀疏的。不过,实际场景中我们多以32位浮点数的形式存储网络权重参数。这一功能能带来多大的性能增益有待观察。
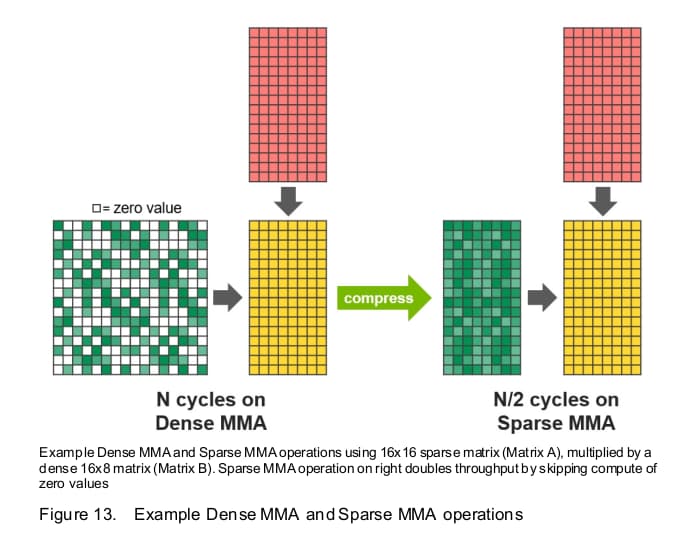
第二项指标针对的是非Tensor状况下的FP32运算。这一运算是在FP32核心下完成的。由于FP32核心的数量6912比V100的5120只多了一点点,所以这是意料之中的性能。
显存基本到位
显存是深度学习关注的重要指标之一,它直接决定了你能训练的batch size大小。我在训练人脸识别模型时,ResNet50在RTX 2080 TI下,112大小的图像样本,最大batch size只能做到128。然而Arcloss官方推荐batch size为256。虽然最后模型幸运的收敛了,但是准确率一直在99%徘徊,无法进一步提升。RTX 30系列的好消息是与2080 TI同等价位的RTX 3090,显存直接做到了24GB!
| 型号 | 显存容量 |
|---|---|
| RTX 3090 | 24 GB |
| RTX 3080 | 10 GB |
| RTX 3070 | 8 GB |
数据来源:NVIDIA官方网站
规格最低的3070显存容量也有8GB。对于常规小型网络训练足够了。
价格有惊喜
RTX 3090售价¥12000起。RTX 3080售价¥5500起。RTX 3070售价¥3900起。其实都很贵,不过与20系列比起来,这个价格优势不小。在价格相当的情况下,3090提供了24GB显存。价格最低的RTX 3070,对于新手入门、个人开发者或者小型商业机构来说,日常的小规模开发完全可以满足需求,性价比极高。如果你仍然觉得这个价格太贵,你不是一个人!2018年没有2080的我,现在也没有。


Comments ()