Segment Anything分割一切的启发式模型
空间域的理解也可以通过基础模型+提示解决吗?

META (FaceBook) AI在2023年4月5日发布了用于图像分割领域的新方案“Segment Anything”(下文简称为SA),中文可以直译为“分割一切”。传统的分割模型训练通常使用监督学习,将原图以及预先标记好的分割区域作为训练输入,训练好的模型仅能分割出训练时标记过的物体。SA则走了另一条不同的路线。使用1100万图像与对应10亿个标记海量数据训练模型,与传统分割模型不同,这个模型同时可以同时接收提示作为输入。于是,训练结束后可以通过设定提示来分割训练数据中不存在的物体。
Introducing Segment Anything: Working toward the first foundation model for image segmentation
We’re releasing the Segment Anything Model (SAM) — a step toward the first foundation model for image segmentation — and the SA-1B dataset.


这种操作像极了ChatGPT这类大语言模型 (Large Language Models)。的确,作者在文章中也明确说明:
In this work, our goal is to build a foundation model for image segmentation. That is, we seek to develop a prompt-able model and pre-train it on a broad dataset using a task that enables powerful generalization.
- Segment-Anything Authors
为达成这一目的,作者提出三大待解决问题:
- 什么样的任务可以实现零样本泛化?
- 与之对应的模型架构是怎样的?
- 驱动该任务与模型的数据是什么样的?
💡
近来的文章中常把“Prompt”译为“提示”,不过我个人认为“引导”、或者“启发”更为合适。
任务方面,作者提出了“promptable segmentation task(启发式分割任务)”。任务的目标为:给定提示信息,返回合理的分割区域。
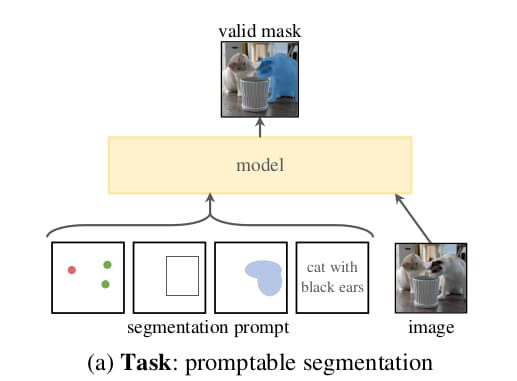
允许的提示信息包括空间信息如位置点、边界框、分割掩模(Mask)以及物体的文本描述。合理的含义则是指对于有歧义的提示,至少给出一个分割区域。在模型的预训练以及后续功能扩展阶段都采用这个任务。
微信扫一扫分享


