多任务合一的RetinaFace
一个规则统一2D、3D任务

封面图片:Kyran Aldworth on Unsplash
本文是对文章 RetinaFace: Single-shot Multi-level Face Localisation in the Wild 的摘抄。该文发表于2019年,作者Jiankang Deng等人提出了RetinaFace:一款多任务合一的人脸检测网络。你可以在这里找到原作者的代码实现与文章原文:
 deepinsight
deepinsight
常规的人脸定位是指寻找一个刚好能够将人脸区域包围的矩形框。这篇文章中作者将人脸定位概念泛化为与人脸相关的任务,例如边界、姿态、特征点、3D网格等。如下图所示。
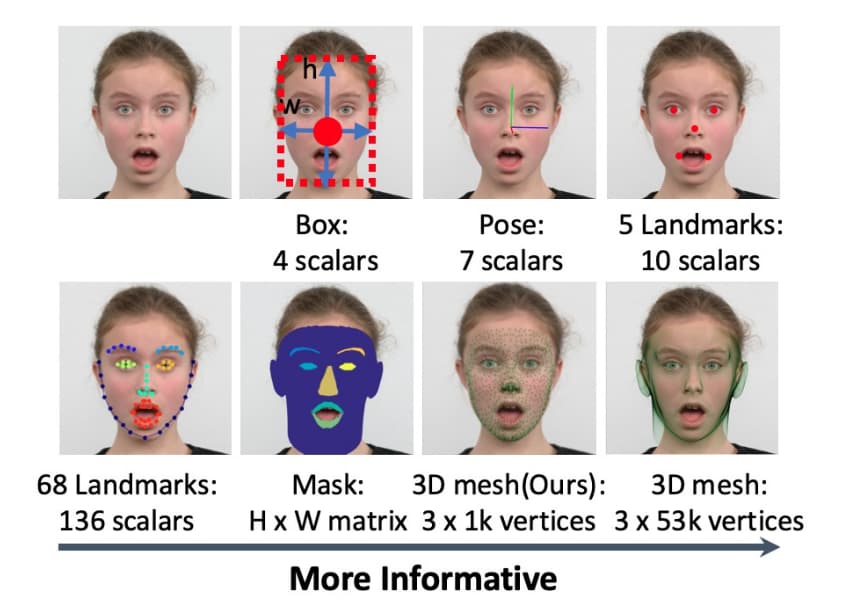
鉴于这些任务均以不同人脸的语义信息为目的,主要不同之处在于信息层级,那么是否可以将这些问题联合求解以便充分利用它们之间的关联信息?
Mask-R-CNN中额外增加的mask分支显著提升了边界框的分类与回归能力。FAN中引入anchor级别的注意力图来提升面对遮挡脸部的检测能力。MFN同时预测边界框与3DMM参数,提升了检测的准确率。然而,3DMM参数的预测与图像层面内含语义信息的点预测相比涉及到了间接的回归目标。这篇文章探讨了基于single-shot架构的不同脸部定位任务的联合训练。文章作者为WIDER FACE训练数据集中的8万4千多个人脸样本标记了5点面部特征点,同时使用半自动标记的方式为WIDER FACE的2万2千个样本、AFLW的2万7千个样本和FDDB的3万9千个样本生成了规模为1k的3D网格。作者发现联合训练可以有效的提升边界框回归的准确度。并将他们关键贡献概括为如下:
- 以图像平面的点回归为目标同时解决面部边界框预测、2D特征点定位与3D网格回归三个问题。
- 提出了基于single-shot思想的训练策略以解决多层面面部回归问题。
- SOTA的结果。
对于3D人脸检测来说,大部分的方案以3DDM参数回归为目标,作者认为这对于图像来说是非直接的信息。即便使用UV空间的方案如DenseReg,相对于图像平面仍然是间接的方式。作者提出以3D网格在图像平面的投影为预测目标,这样就与另外两个任务在信息层面趋于一致。
3D人脸重建
下图展示了由N个顶点构成的三角形网格。由于顶点的拓扑机构固定,它们与3D人脸之间形成了像素对应关系。顶点数量越多,细节越丰富。作者选择回归N+68个顶点来表示面部的三维结构,并定义顶点loss如下:
$$ L_{vert} = \frac{1}{N} \sum^N_{i=1}||V_i(x, y, z) - V^*_i(x, y, z)||_1$$
其中N的值为1103。
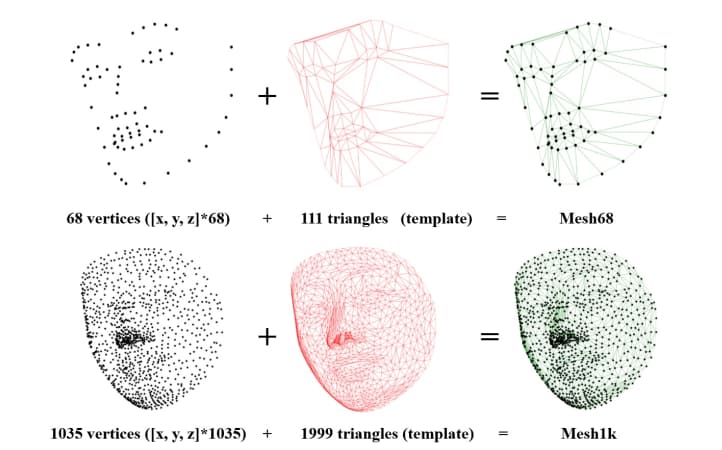
由于3D网格投影在二维平面时,z坐标所含的信息不如x、y那么直观。所以作者根据3D网格的拓扑信息定义了边长loss:
$$L_{edge} = \frac{1}{3M} \sum^M_{i=1} ||E_i - E_i^*||_1$$
其中M=2110,是三角形的数量。E是预测的边长,E* 是实际边长。最后得到整体loss为:
$$L_{mesh} = L_{vert} + \lambda_0 L_{edge} $$
注意作者根据实验结果将$\lambda_0$的数值设为1。
多层级面部定位
对于任意anchor,多任务损失函数定义为:
$$L=L_{cls}(p_i,p^*_i)+\lambda_1p^*_iL_{box}(t_i, t_i^*)+\lambda_2p_i^*L_{pts}(l_i,l_i^*)+\lambda_3p_i^*L_{mesh}(v_i,v_i^*)$$
分别是边界框、五点坐标与1k顶点的损失函数,其中*代表标记数据。$p_i$为anchor对人脸的预测,1为positive,0为negative。分类损失为softmax。边界框的学习目标与Faster R-CNN类似,转换为$\log(w^*/s ^a)$与$\log(h^*/s^a)$,其中$w$与$h$为人脸边界框的宽与高。另外,全部任务的点回归目标统一为:
$$x_j^*-x_{center}^a)/s^a$$$$y_j^*-y_{center}^a)/s^a$$$$z_j^*-z_{nose-tip}^a)/s^a$$
其中x, y对应平面内坐标,z对应了1k顶点的z轴坐标,并以鼻尖处为0。最后z坐标还要针对anchor scale归一化。$\lambda_1$ ~ $\lambda_3$ 都为1。
作者采用这种设计背后的逻辑为:边界框、面部5点乃至1k顶点的回归任务本质上是一致的——图像平面内的点回归。只是任务的信息量不同。因此这些任务彼此之间可以相互促进。所以,作者所说的多层级中的层级实际上是指信息量的层级。
单次多级面部定位
下图展示了作者提出的RetinaFace网络结构。该网络包含三个主要部分:特征金字塔,语境分支与级联多任务损失。
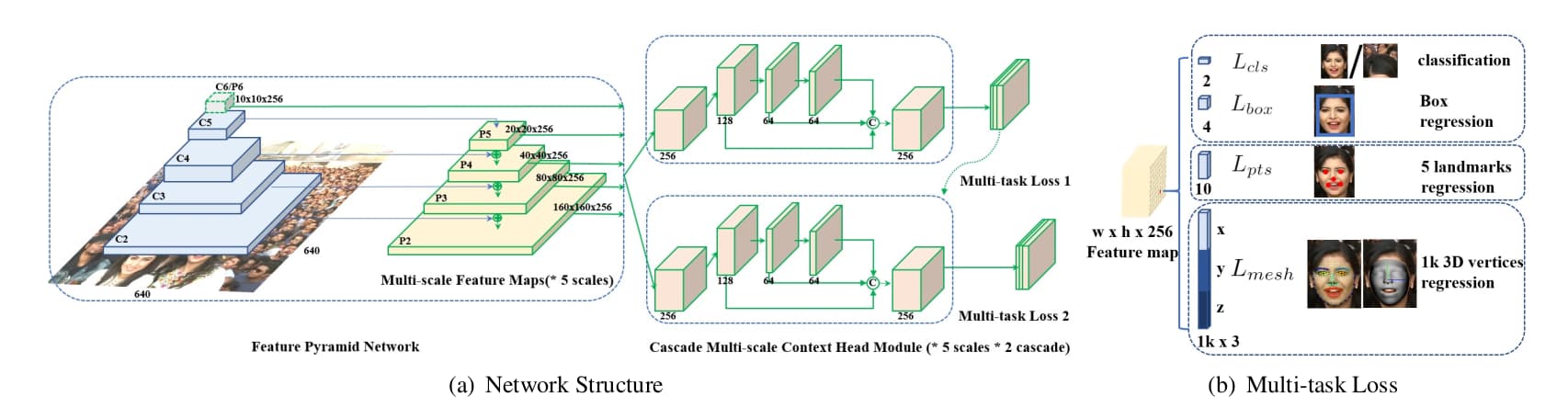
图像经过特征金字塔生成5个尺度的特征图,语境分支根据特征图计算多任务损失函数。第一个语境分支根据常规anchor预测边界框,第二个语境分支根据前一个分支回归后的anchor预测更加准确的边界框。类似RetinaNet,这也是一个全卷积神经网络,不同之处在于回归子网络的设计则将3×3卷积替换为deformable convolution network,并采用了级联的方式对边界框做了两次递进的回归。在anchor设定与匹配规则方面,RetinaFace的scale阶梯为21/3 ,ratio为1:1。当输入为640×640像素时,检测尺度范围为16 ~ 406像素。这里可以看出RetinaFace看中小尺寸人脸的检测,总数102300个anchor中,有75%来自P2 。匹配同样是基于IoU实现的,对于第一级语境分支,大于0.7为positive,小于0.3为negative;对于第二级,大于0.5为positive,小于0.4为negative。未匹配的anchors全部忽略。另外作者没有使用Focal loss,而是使用了实时困难样本挖掘。
数据集
作者重新标记了WIDER FACE数据集,但是取决于图像清晰度,并非所有的人脸都有特征点标记。对于1k顶点的生成,作者首先将68个面部坐标点转换成三维坐标,并据此得出3DMM参数,进而重建了包含53k个顶点的稠密三维网格。重建过程中还会与UV材质图像比较,有必要的话重新标记68点。如果结果还不尽如人意则弃用。最后获得了训练集下22k个准确的3D面部标记。同样的逻辑也被应用在AFLW与FDDB数据集上。
实验细节
数据增强方法包括:随机裁切并缩放至640×640像素,随机水平翻转,色彩畸变。训练优化器为SGD,momentum=0.9, batch size为32,训练在4块P40GPU下完成。起始学习率为10e-3,5个epoch之后上升至10e-2(我的理解为warmup),之后在10、55和68个epoch后缩小10倍。
与其它网络的具体比较这里不再列出,感兴趣的话可以阅读原文。
总结
RetinaFace将信息量不同的任务统一为图像平面内的点回归任务。实验显示这些信息层级不同的任务在训练时可以相互促进。
个人观点
RetinaFace不仅仅是一个人脸检测器,还可以输出5个特征点坐标,以及1k级别的三维顶点坐标。这是一个与人脸几何相关的集成方案。网络结构本身的设计并没有太颠覆的地方。数据集应该是最大的亮点。需要注意作者释出的数据仅包含边界框与面部五点坐标,所以数据恐怕是复现最大的难点。
微信扫一扫分享



评论 ()