基于深度学习的人脸特征点检测 - 背景
为什么我决定采用深度学习实现面部特征点检测。

人脸检测与识别一直是机器学习领域的一大热点。人脸检测是指从图像中检测出人脸区域。人脸识别则是判断特定的脸部图像是否与某个人对应。现实生活中人脸检测与识别有着多种应用场合,例如iPhone X所搭载的FaceID功能,用户只需瞄一眼手机,即可自动解锁。

有众多方法可以实现人脸检测,例如大名鼎鼎的Viola Jones算法以及近几年大热的深度学习。如果你感兴趣可以查看这两种方法在OpenCV中的开源实现[1], [2]。
由于在实际情况中捕捉人脸的正面图像是比较困难的,因此在人脸检测后通常会附加一个步骤叫做“人脸对齐”。在该过程中需要针对人脸图像中的特征点进行检测,标记出一些特定区域例如眉毛、眼角、嘴角等。这种特征点检测行为被称为“Facial landmark localization”。人脸特征点检测也有众多的开源算法,这里我推荐两个。一个是Dlib[3],一个开源的C++代码库。另一个是OpenFace[4],来自CMU的Tadas Baltrusaitis。
当特征点检测完成,我们就可以在图像中标记出人脸的具体位置,甚至可以估算出人脸的朝向姿态。下图是我用Dlib与OpenCV的实现。完整的视频请参考YouTube视频,国内请参考这里。
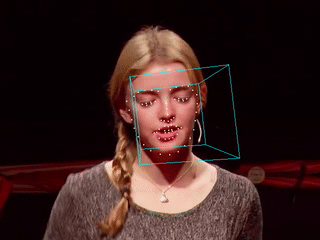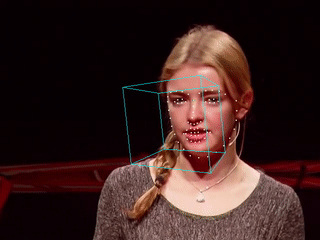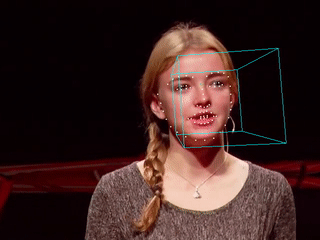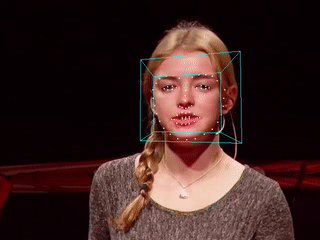
正如你所看到的,人脸姿态的估计并不完善,在一些角度上可以看到大幅度的抖动。对源码进行分析后发现抖动主要是由于面部特征点的抖动造成,尤其是位于下颌的特征点。使用卡尔曼滤波可以在某种程度上消除抖动,但是如果要用在视频中的话,过于强调稳定的卡尔曼滤波会使得标记点无法及时跟上移动中的面部,效果反而变得更差。
这个也很好理解,当前的方法采用了逐帧检测的方式,每一帧在算法看起来都是“新的”,且移动过程中的人脸图像存在微小的变化,这些变化最终体现在了特征点位置的扰动上。要想消除扰动,一种思路是利用视频帧与帧之间物体空间位置上的连续性,另一种思路则是提高特征点检测的稳健性。
所以,究竟应该采用哪一种方法呢?
微信扫一扫分享



评论 ()