全面发展的EfficientNet
全维度的模型缩放手段

封面图片:lalo Hernandez
EfficientNet是由Mingxing Tan等人在2019年发表的文章 EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 中提出的一种模型规模缩放方案。你可以在这里找到原文:
以下内容为针对该文章的读书笔记。
通用的缩放规则
考虑计算资源限制与要解决的问题复杂度,同一种卷积神经网络架构会提供不同参数规模的实现。例如MobileNet在网络的宽度上做文章,也就是缩放通道数。ResNet在网络深度上缩放,小一点有ResNet18,大一点有ResNet101。还有一些在图像分辨率上实施缩放操作。这三种方式如下图b、c、d所示。
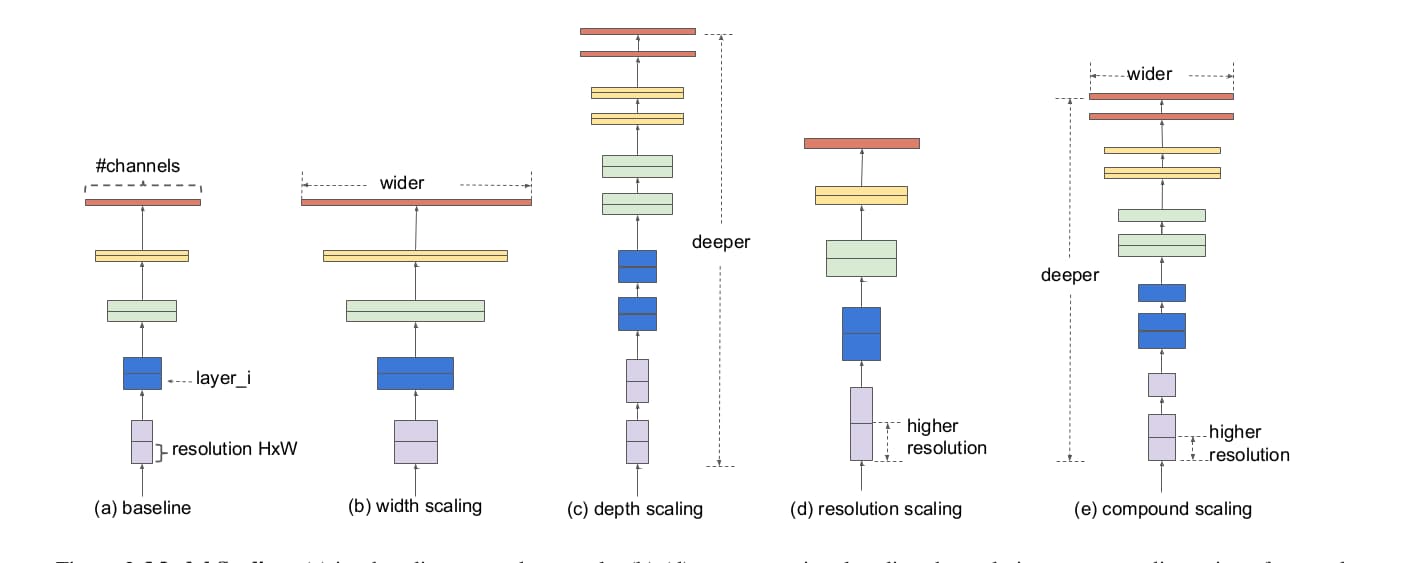
虽然网络在这三个维度上都可以缩放,但是过往的缩放经常在单一维度上进行。这是因为多维度同时缩放需要大量的手工调试工作。因此,是否存在某种通用的缩放规则,可以同时达成高准确率与高效率,是这篇文章要解决的问题。
缩放的维度
以ImageNet为代表性应用,获得高准确率的模型往往以大规模的参数为代价。另一方面,神经架构搜索已经在以效率为目标的小规模神经网络结构优化上崭露头角。但是这种方法面对拥有较大设计空间与高调教成本的大规模网络则显得力不从心。为此,作者回归到模型缩放这一手段。大多模型是由不断重复堆叠的模块构成的。模型缩放并非要改变这些基础模块的逻辑构造,而是在不同的维度改变它们的规模。
深度是第一个方面。大多数网络在规模缩放时会首先考虑深度。不过梯度消失依旧会对网络训练造成不利影响,ResNet1000并没有比ResNet101好太多。宽度是另一个维度,也是众多小型网络最爱的缩放维度。更宽的网络能够捕捉到更加丰富的细节,只是深度不足会导致高阶特征不足。提升分辨率也是提升性能的手段,不过也逃不出边际效应递减的规律。
为此,作者提出了第一点观察报告:对网络任一维度的放大能够改进模型准确率,但是改进的程度随模型规模扩大而逐渐消失。
所以对模型的缩放应当在不同的维度同时进行。例如当模型的输入分辨率变大时,更深层的模型具备更大的感受野与之匹配。而更宽的模型可以同时提供更多的细节。作者的实验印证了这么做的有效性,同时缩放下模型更不容易饱和。
为此,作者提出第二点观察报告:在网络缩放时,平衡的宽度、深度与分辨率对于准确率与效率至关重要。
复合缩放法
在以上观察的基础上,作者提出了复合缩放法。使用复合参数 $\phi$ 统一缩放网络的宽度、深度与分辨率。
$$\text{深度:} d=\alpha^{\phi} \\ \text{宽度:} w=\beta^{\phi} \\ \text{分辨率:} r=\gamma^{\phi} \\ \alpha \cdot \beta^2 \cdot \gamma^2 \approx 2 \\ \alpha \geq 1, \beta \geq 1, \gamma \geq 1$$
其中,$\alpha, \beta, \gamma$ 可以通过网格搜索来获得。这种方法中 $\phi$ 控制了整体规模,$\alpha, \beta, \gamma$ 可以看做是参数分配的权重。
新基础架构EfficientNet
缩放的方法有了,还需要一个好的基础架构作为底子。作者采用神经网络架构搜索的方法以准确率与运算量为目标搜索了可行的网络结构,获得了EfficientNet-B0。要注意作者选择运算量而非时延。
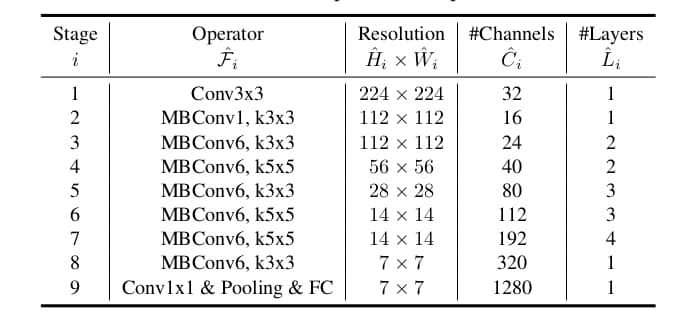
在EfficientNet-B0的基础上,使用以下两步法缩放网络。
第一步:固定参数$\phi$,假设有双倍的运算资源,通过网格搜索获得$\alpha, \beta, \gamma$。
第二步:固定\alpha, \beta, \gamma$,缩放$\phi$来扩增规模。
如此,最终获得EfficientNet B1-B7这七种不同规模的模型。
总结
EfficientNet为构建网络架构提出了一种思路:首先构建规模较小的基础模型,然后通过统一的缩放规则放大模型规模。对模型的三个维度实施统一缩放是这篇文章的核心思想。在实际项目中可以借鉴。
EfficientNet已经内嵌在了TensorFlow中,可以通过Keras API直接调用。另外,将该缩放思想用在物体检测上就可得到EfficientDet。如果你感兴趣可以看这里:
 Yin Guobing
Yin Guobing


