高分辨网络HRNet
物体检测首选骨干网

这是来自微软的一篇论文,介绍了一种非常适合于与空间位置相关的视觉任务例如物体检测、分割的神经网络结构。官方已经开源在了GitHub上:


以下是对论文核心内容的摘抄。
以分类为目标的神经网络结构几乎都遵从了LeNet-5的设计灵感:随着网络的深入,逐渐降低特征图的空间分辨率。但是对于位置敏感的任务例如物体检测来说,高分辨率的空间特征是非常重要的。这启发了一系列新的网络架构如U-Net等。他们使用神经网络逐渐提升特征图的空间分辨率,有效的改善了相关任务下神经网络的表现。
高分辨网络(High-Resolution Net, HRNet)在运算全部过程中都可以保持高分辨表征。它始于一组高分辨率卷积,然后逐步添加低分辨率的卷积分支,并将它们以并行的方式连接起来,如下图所示。最终的网络由若干阶段组成,其中第n段包含n个卷积分支并且具备n个不同的分辨率。在整个过程中并行的运算组合间通过多分辨率融合不断地交换着信息。

以这种方式获得的高分辨表征不仅仅习得了健壮的语义特征,在空间维度上的准确性也表现良好。第一,不同分辨率分支并行连接而非串行,因此整个网络都保留了高分辨表征;第二,传统方式将高分辨率低阶特征与放大的低分辨率高阶特征相融合,而HRNet则始终保留了高分辨率与低分辨率特征,并且不断的让两者相融合,相互促进。
HRNet有两个版本,HRNetV1仅仅输出高分辨率卷积分支的结果,用在人类姿态估算任务中。HRNetV2则结合了所有并行的分支,用在图像分割中。此外还有HRNetV2p,将其高分辨分支的分层输出用在检测任务中可以有效的提升微小物体的检测效果。
相关工作
从三个不同角度分析回顾过往研究工作。
低分辨表征学习
通过去除分类网络的全连接层,并结合中间层中等分辨率特征图,可以改善高阶特征图在物体分割应用上的表现。对于全卷积神经网络则将步长卷积与相关卷积层替换为空洞卷积。并进一步通过特征金字塔提升不同尺度下的分割效果。
复原高分辨表征
对于已经获得的低分辨表征,可以通过上采样的方式逐渐恢复高分辨率表征。上采样的网络结构可能与降采样相对称,如VGGNet,还可以在镜像层之间添加跳跃连接,如SegNet,甚至可以直接拷贝特征图,如U-Net等。
非对称的上采样过程也有大量的研究。RefineNet将同等分辨率下采样特征图的副本与上采样特征图融合。其它方法还包括:在骨干网络中使用空洞卷积配合轻量的上采样过程;轻下采样配合重上采样;通过卷积单元改进跳跃连接,将低分辨率的跳跃连接信息传送到高分辨率跳跃连接;通过全连接堆叠多个U-Nets等。
保留高分辨表征
类似的工作包括:convolutional neural fabrics、interlinked CNNs、GridNet以及multi-scale DenseNet。前两者没有精心选择低分辨分支的起点、交换通道、没有采用BatchNorm以及残差连接。GridNet里高低分辨率分支信息的融合是单向的。Multi-scale DenseNet里的高分辨分支则没有接收到任何低分辨的信息。
多尺度融合
最直观的多尺度融合无疑是将多尺度图像分别馈入不同的神经网络并综合各自的输出。U-Net、SegNet等将同等分辨率的降采样过程中的低阶特征与上采样过程中的高阶特征通过跳跃连接融合。PSPNet与DeepLab V2/3通过pyramid pooling与atrous spatial pyramid pooling获得金字塔特征并融合。HRNet的不同之处在于融合输出包括四个不同的分辨率,而非一个;融合过程多次重复出现。
高分辨网络
网络的起始部分为两层stride2的3×3卷积,将分辨率降低到输入的1/4。之后是网络主体,最终的输出具备同等分辨率。网络主体由多个部分组成:并行的多分辨率卷积分支;多次重复的多分辨率融合;表征分支。
并行的多分辨率卷积
网络主体始于一个高分辨率卷积分支。随着分辨率的下降逐个添加新的卷积分支,并将他们并行地连接起来。这样网络的后段将会额外增加一个低分辨率分支。第s个阶段的r个卷积的分辨率是输入分辨率的 \( 1/(2^{r-1}) \)。
重复的多分辨率融合
融合的目的是在多分辨率表征之间交换信息。由于分辨率不同,低分辨率表征在接收高分辨率信息时需要通过stride卷积来降低分辨率。同样的道理,高分辨率表征在接收低分辨率信息时需要通过双线性上采样与1×1卷积来提升分辨率与通道数。如下图所示。
表征分支
按照表征分支的不同,网络可分为三类。如下图。
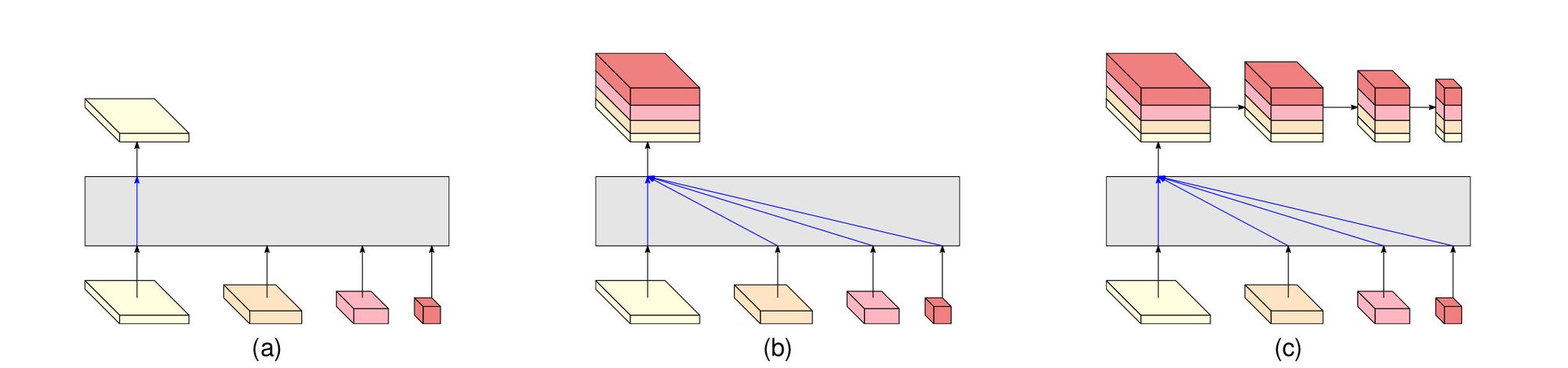
(a) HRNetV1,输出仅仅采纳了高分辨率分支。其他分支忽略。
(b) HRNetV2,低分辨部分通过双线性上采样提升分辨率,堆叠在一起,之后通过1×1卷积融合。
(c) HRNetV2p,将HRNetV2的输出降采样处理,得到多个尺度输出。
网络配置
网络主体包含四个阶段、四个并行卷积分支。分辨率分别为1/4、1/8、1/16和1/32。第一阶段包含4个宽度为64的bottleneck残差单元,每个后边跟随3×3卷积,将特征图的数量变为C。第2、3、4个阶段分别包含1、4、3个模块。每个模块包含4个残差单元。每个单元为每个分辨率提供两个3×3卷积,其后跟随BatchNorm与非线性激活ReLU。四个分辨率下的卷积通道数依次为C、2C、4C和8C。每个阶段的末尾存在多分辨率融合模块,表格中未列出。
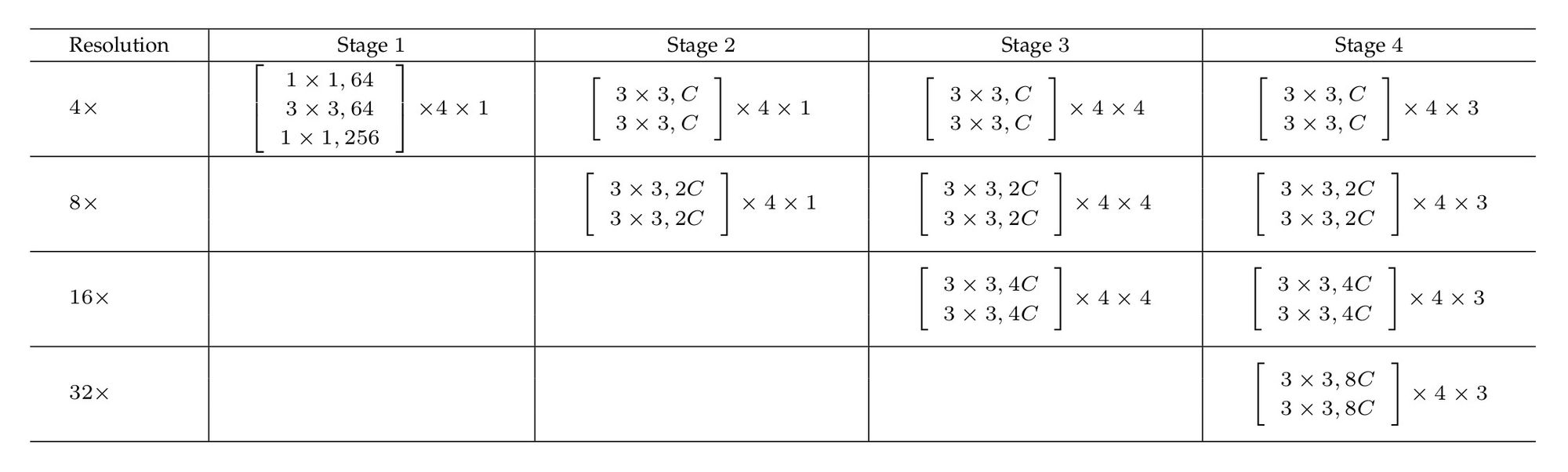
表中公式的含义:方括号内为模块结构,第二个数字为残差单元的个数,第三个数字为模块的个数。
分析
每个模块可以分为两部分:(a) 多分辨率并行卷积,(b)多分辨率融合。
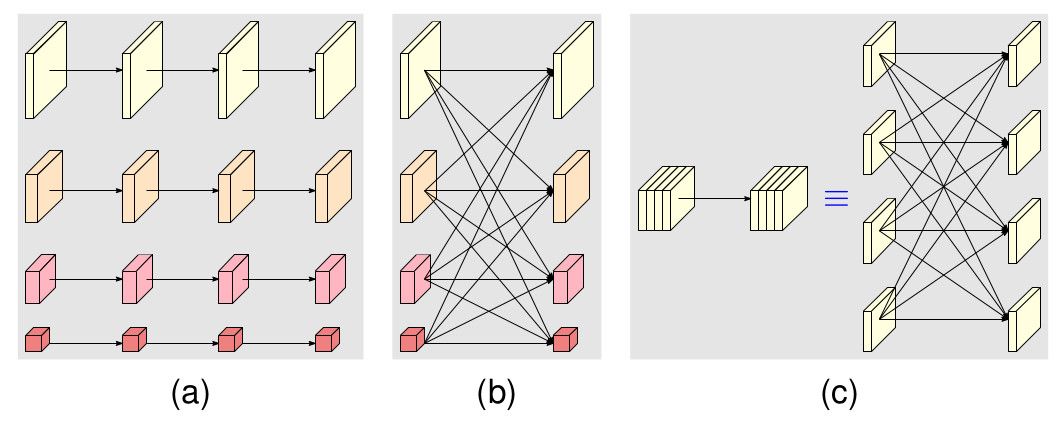
多分辨率并行卷积类似群卷积(group convolution)。不同分辨率的卷积运算相互隔离,且分辨率保持不变。多分辨率融合则类似常规卷积的多分支全连接方式(c)。一个常规卷积可以被拆分为多个小卷积。输入通道被拆分为若干子集,输出通道同样被拆分为若干子集。输入子集与输出子集以稠密方式连接,每个连接都是常规卷积运算。每个输出通道的子集都是针对每个输入通道子集的卷积输出的综合。唯一的区别在于HRNet需要处理分辨率差异的问题。
实验数据
在物体检测、人体姿态、人脸对齐等任务下的训练过程与测试数据。此处省略,轻查阅原文。
总结
HRNet的三个核心:1、以并行而非串行的方式连接不同分辨率的分支;2、整个运算过程都保留了高分辨率表征;3、不断地融合不同分辨率的表征,得到对位置敏感的高分辨率表征。
HRNet证明针对特定的视觉任务,设计全新的网络结构胜过从现有的低分辨率网络扩展。
我觉得这个网络也有必要手动实现下。如果你关注的话可以在这里看到进展:
yinguobing

Comments ()