TensorFlow模型剪枝原理
剪枝技术背景与细节

本文是对论文“To prune, or not to prune: exploring the efficacy of pruning for model compression”的摘抄。这篇文章是TensorFlow模型优化工具文档中推荐的,作者Michael H. Zhu,来自斯坦福大学。在这里可以找到论文原文。
背景
对于资源有限的移动终端设备来说,内容带宽通常是一个重要的限制因素。模型压缩至少有两点好处:减少耗电的内存访问次数;同等带宽下提升压缩模型参数的获取效率。剪枝将不重要的模型权重归零,实现了模型压缩的同时只带来了较小的质量损失。剪枝之后的模型是稀疏的,在支持稀疏矩阵加速运算的硬件上可以进一步获得加速效果。
国冰提示:
英伟达的第三代张量核心(Tensor Core)对于稀疏矩阵的运算有约5倍的性能提升。这一点我们在文章“深度学习要买RTX3080吗”中有过介绍。
 Yin Guobing
Yin Guobing
在模型内存足迹(memory footprint)一定的前提下,如何获得最准确的模型,是本文的核心内容。作者通过对比两种模型来回答这个问题。第一种,先训练一个大模型,然后通过剪枝将其转换为一个强稀疏模型;第二种,直接训练一个非稀疏模型,尺寸与稀疏模型相当。在具体的模型架构与任务上,作者做出以下选择:
- 图像分类:Inception V3与MobileNets
- 序列分析:stacked LSTMs与seq2seq
相关工作
90年代的剪枝通过将权重置零时网络损失函数增量的二阶泰勒级数近似来实现。最近的工作中,基于数量级的权重剪枝开始流行。这种方式简单易行,并且适用于大型网络与数据集。本文通过剪去最小数量级的权重来控制模型稀疏程度。这种策略不需要人工选择权重阈值,不仅适用于CNN也可以用于LSTM。
方案
作者在TensorFlow的基础上实现了训练中剪枝。针对每一个选定的layer,增加同尺寸同形状的二元mask变量作为该layer的权重张量,并决定在哪个权重参数参与网络的前向传播。同时,在训练图中注入算子对该层的权重按照绝对值大小排序,将最小的权重置零直到该层的稀疏程度达到预定指标。反向传播的梯度同样会经过该二元mask,但是不会更新被置零的权重。
稀疏程度随着训练的进程逐渐增加,并满足公式:
$$ s_t=s_f+(s_i-s_f)\left (1- \frac{t-t_0}{n \Delta t} \right)^3 $$
其中$s_i$为初始稀疏率,$s_f$为最终稀疏率,$n$为修剪总步数,$t$为训练步数,$\Delta t$为修剪频率。
二元mask每$\Delta t$更新一次,这有助于网络的准确率从修剪后的状态逐步恢复。作者的实验表明当$\Delta t$的取值在100到1000之间时剪枝对最终的模型质量影响可以忽略。一旦模型达到预定的稀疏指标,权重mask停止更新。按照稀疏率变化公式,训练早期频繁剪枝,随着训练进展,剪枝的频率越来越低——因为可供剪枝的权重越来越少。如下图所示。
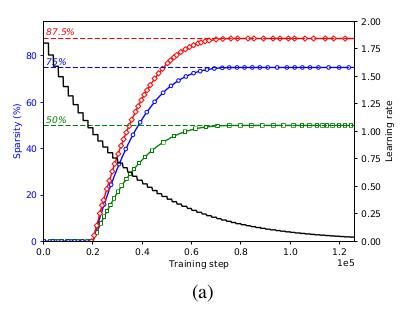
实际剪枝过程中,网络会先训练若干epoch或者加载一个已经训练好的网络,这就决定了$t_0$。参数$n$则很大程度上取决于学习率曲线。作者观察到随着学习率的下降,剪枝后的模型准确率可能会很难恢复过来。反过来,过高的学习率则可能导致权重在收敛到较优值之前被剪掉。因此需要将两者紧密结合起来。例如上图中,对Inception V3剪枝的过程安排在学习率相对较大的阶段。
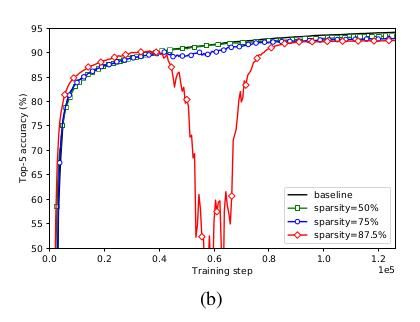
下图则展示了训练过程中模型准确率的变化。对于稀疏率达87.5%的模型,随着稀疏程度的上升,模型经历了“几乎灾难性”的衰退,但是随后又很快恢复了过来。这种现象在高稀疏率的模型中更加常见。
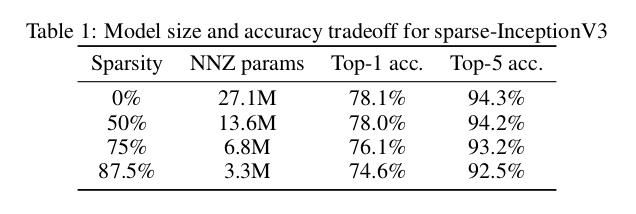
下表展示了稀疏程度与模型准确率之间的关系。随着稀疏程度的增加,模型的准确率开始下降。不过即便有一半的权重被裁剪,模型的准确率也只下降了一点。
比较“大稀疏”与“小密实”模型
MobileNets
对于紧凑模型来说剪枝仍然是有效的,可以与width multiplier相比。同等大小的模型,稀疏模型优于非稀疏模型。训练也很简单,只是初始学习率小10倍。
国冰提示:
这一章节的模型都为常见模型,且数据较多,因此只说结论。感兴趣的读者可以查阅原文。另外两个子章节涉及模型与图像无关,故此跳过。
讨论
稀疏模型的内存足迹包括非零参数的保存以及索引它们所需的数据结构。模型剪枝可以减少非零参数之间的连接数,但是稀疏矩阵的存储不可避免的减小了压缩率。无论权重是否为0,二元mask稀疏矩阵都需要为之存储1bit,同时还需要一个向量存储非0值。无论稀疏率的大小,这部分开销无法避免。
另外,大稀疏模型比同体积非稀疏模型的表现更好。而且随着模型规模的扩大,这种差异越发明显。
总结
经过剪枝之后的稀疏大模型要优于同体积的非稀疏模型。作者提出的递进剪枝策略可以广泛的应用于各种模型。有限资源环境下,剪枝是有效的模型压缩策略。深度学习加速硬件应当将稀疏矩阵的存储与运算提供支持。
(全文完)
TensorFlow支持剪枝,轻参阅官方文档:
针对HRNet的剪枝可能会晚一点。因为目前剪枝不支持 subclassed model。参见issue:
 tensorflow
tensorflow
微信扫一扫分享



评论 ()