Docker环境下开发TensorFlow模型
充分发挥Docker优势高效开发TensorFlow模型

前几天写了一篇使用VSCode Remote配合远程Docker容器开发TensorFlow模型的文章。如果你还没看并且感兴趣的话可以看这里:
 Yin Guobing
Yin Guobing
如果使用上篇文章介绍的使用方式来开发模型,仍然有大量的工作要做,例如:
- 需要在容器内手动安装其它依赖包。
- 需要把大量的数据传输到容器内部。
- 如果有多个任务使用到同一个数据集,需要单独拷贝副本,占用大量空间。
实际上上篇文章中的使用方式是把Docker容器当作了虚拟机使用。但是与虚拟机相比,容器服务是一种更加轻量化的虚拟方式。所以在使用时应该特别注意它的特性,以最大化利用效率。经过一番思考与尝试,我在上篇文章的基础上改进了Docker环境下开发TensorFlow模型的方式,它具备如下特点:
- 使用VSCode Remote实现远程模型开发。
- 数据集可以在不同的容器之间共享。
- 充分利用容器服务解决开发环境适配问题。
充分利用容器服务可以实现在一台机器上同时使用不同开发环境,例如同时运行TF1与TF2,而且是在不同的CUDA与cuDNN版本上。接下来是具体的实现方法。
Tips:本文以TensorFlow为例,你也可以以此为参考配置PyTorch开发环境。
整体架构
开发环境依旧是本地PC+远程服务器的方式。主要的运算工作都在远程服务器完成。本地使用VSCode实现代码编写与调试。为了实现数据集在不同容器内的共享,在容器内使用 Volume 的方式加载数据集存储空间。考虑到调试的便捷性,使用 bind 的方式加载代码存储空间。
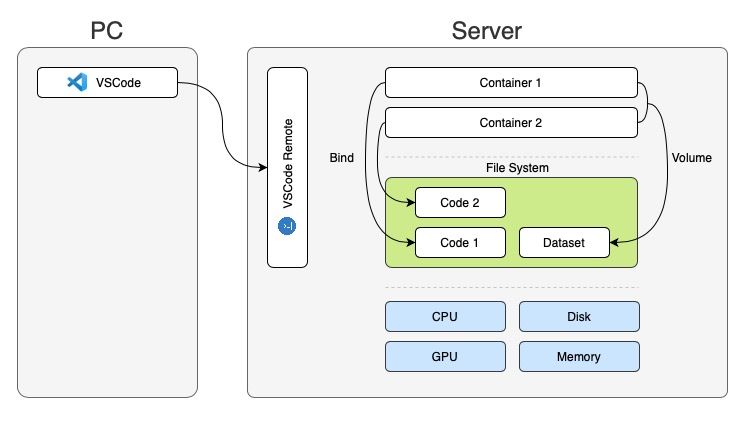
在了解了整体架构后,接下来的内容将介绍具体的实现过程。
构建Docker镜像
TensorFlow官方在Docker Hub上提供了TensorFlow容器镜像。这些镜像主要解决了GPU环境下的CUDA与cuDNN的适配问题。实际情况中项目往往还会使用一些第三方库,例如OpenCV等。由于官方镜像不包含这些库,我们需要自行构建任务运行所需的Docker镜像。
构建Docker镜像并不需要从零开始。例如在这个项目中你使用OpenCV来实现图像数据增强,则可以在TensorFlow官方镜像的基础上安装OpenCV即可。Docker镜像的制定主要通过 Dockerfile 的方式实现。
假设你的模型开发目录如下:
.
├── model.py
└── train.py其中 model.py 存储了模型实现, train.py 为训练入口。此时在该目录下新建一个 Dockerfile 文件。并在其中填充如下内容:
# syntax=docker/dockerfile:1
FROM tensorflow/tensorflow:2.5.0-gpu
RUN pip3 install opencv-python文件中的 FROM 后跟随的是你的基础镜像。这里使用了TensorFlow官方释出的TF2.5 GPU镜像。第二行的 RUN 命令使用pip来安装缺少的OpenCV库。如果你的项目中还用到了其它Python库,可以参照类似的方式添加。
Tips:你可以在Docker Hub上找到适配各种环境的Docker镜像。
训练时,Docker将使用该镜像新建容器。在上一篇文章中,接下来会使用 docker run 命令启动容器,然后在容器内开展模型开发工作。但是在本篇文章中,为了保证训练任务的顺利高效进行,我们将采用另一种容器使用方式。
使用Docker Compose部署容器
使用Docker容器最便捷的方式无疑是通过 docker run 命令来启动。但是由于本文中的开发环境同时涉及到了镜像、端口、存储、命令等参数, docker run 命令后会跟随一大堆参数;不仅如此,当需要共享代码时,需将该命令想办法存储在对应的文档中。
使用Docker Compose应用可以简化这部分工作。Docker Compose通过使用配置文件的方式取代了传统的 docker run 命令。在配置文件撰写完成后,只需要使用 docker-compose up 命令即可启动容器并执行指定任务。该配置文件是用 YAML 格式,因此可以使用Git将其纳入版本管理系统。
在上一步建立Dockerfile文件后,当前开发目录结构如下:
.
├── model.py
├── train.py
└── Dockerfile这一步需要新建一个 docker-compose.yml 文件。然后在文件的第一行内容填入:
version: "3.9"这一行表明了配置文件版本。接下来我们将在文件中填充两部分内容,以实现模型训练任务。
定义服务
一个运行中的Docker容器可以看作是一项服务。在本文中我们要建立的服务为模型训练。在这里将其命名为 train 。在文件中继续添加以下内容,定义 train 服务:
services:
train:当前模型的训练环境我们已经在上一步中通过Dockerfile的形式定义完成。但是它只是一个容器定义,所以这里需要使用 build 命令构建容器。命令后的点符号代表了当前目录,docker会自动寻找 Dockerfile 。
services:
train:
build: .训练任务通常以一个Python命令开启。在文件中通过 command 来指定要执行的命令。
services:
train:
build: .
command: python3 /code/train.py这里你可能会有疑问,命令中的路径 /code 是怎么来的?这就涉及到了下一步,为Docker容器挂载存储。先看具体的实现方法:
# 在之前的文件后追加:
volumes:
- type: volume
source: faces_emore_tfrecord
target: /data
volume:
nocopy: true
- type: bind
source: .
target: /code上边配置使用 volumes 来定义存储空间,并通过短横线 - 来区分多个空间。
type 用来指定存储类型。Docker容器的存储有多种类型。在这里,第一个存储空间使用 volume 的方式,这种方式非常适合用来存放训练用的数据集,方便不同的容器共享使用。 source 代表了存储空间的来源。示例中为 faces_emore_tfrecord ,这实际上是Docker为我们管理的一块永久存储空间,稍后会涉及它的建立方式。 target 定义了当前存储空间在容器内的具体路径。我把它设定为 /data 以方便训练时使用。volume 下可以设定额外的参数。同理,第二个存储空间将当前代码目录绑定到容器内的 /code 目录下。这也是之前训练任务使用的目录位置。
接下来需要为该容器启用GPU支持。继续在文件后追加以下内容:
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]最后一行代码将使所有GPU对容器可见。
至此,容器的第一个服务定义完成。
定义永久存储
在文件的最后追加以下内容:
volumes:
faces_emore_tfrecord:这里 faces_emore_tfrecord 为该永久存储的名字。用于训练的数据集可以放置在这里。
以上即为使用Docker训练的全部配置过程。该过程结束后即可在当前目录下启动训练任务:
docker-compose up之后耐心等待任务结束即可。
其它资料
你可以在官方网站找到更多关于Docker Compose的内容。


Comments ()