
召回、误报、准确率、ROC、PR、混淆矩阵都是啥意思?与张小白一起,掌握模型评价的科学方法。
即将从火星大学毕业的张小白在火星基地某公司寻得一份与人工智能相关的实习机会。该公司作为火星安保服务的供应商,正在试图使用机器来替代人工实现幽灵猫与幽灵狗的自动检测。众所周知,这两种生物是人类移民火星之后的意外产物。早期移民携带的宠物在火星上突然进化出了“穿墙”的超能力。为了防止它们在基地中随意穿越导致基础设施如火星电厂的损坏,人类花了不少功夫。
张小白面临的第一个任务就是制作一款幽灵猫狗分类器。这并非难事,张小白花了一个上午的时间便完成了一款基于深度神经网络模型的幽灵猫狗分类器训练。就在他将模型灌入便携终端的时候,旁边的同事好奇的问了一句:“这个模型准吗?”
“当然准了!”。张小白嘴上这么回答,但是心里有点发虚。准,是多准呢?
用数字来说话
虽然是一名实习工程师,但是张小白依旧清晰记得火星大学的导师反复强调过:要用数字来说话。正好今天上午基建维护小队传送回来一组最新数据,张小白清点了一下,在里边发现了100张幽灵猫的照片。用这100张照片来测试一下模型的表现,认出的幽灵猫越多,说明模型越准。
想到做到,张小白迅速将这100张照片用作测试数据馈入到模型的输入端。眨眼间,全息终端的显示屏上打印出了模型的预测结果。张小白清点了一下,100张幽灵猫的照片中,有98张被归类为幽灵猫,有2张被归类为幽灵狗。那么准确率应当是:
$$准确率=\frac{正确分类为幽灵猫的照片数量}{幽灵猫照片总数}=\frac{98}{100}=98\%$$
测试结果一出来,张小白便迫不及待的喊旁边的同事过来看结果。
“可以啊,98%准确率!不过,为啥你这都是幽灵猫的照片呀?要是换成幽灵狗的照片,也是这么准吗?”
一个模型,两种错误
一语点醒梦中人。猫狗分类器的本质是一个二元分类器。正常情况下,输入的图像有两种:要么是猫的照片,要么是狗的照片;模型的输出也只有两种结果——要么是猫,要么是狗。两种输入与两种输出相组合,模型的行为最终会产生四种结果:将猫认成猫✅;将狗认成狗✅;将猫认成狗❎;将狗认成猫❎。
张小白的这次测试中仅仅使用了100张幽灵猫的照片,所以,他的测试结果也只有两种状况:将猫认成猫,将猫认成狗。由于幽灵狗样本的缺失,本次测试是不完备的,无法全面反应模型表现。
经过同事的提醒,张小白联系到了在维护小队工作的同学,又额外找来了100张幽灵狗的照片。他将这100张幽灵狗的照片也输入到模型。短暂的等待后,模型输出了结果:100张幽灵狗的照片,有85张预测为狗,15张预测为猫。
至此,这四种结果的数量可以使用一个表格来呈现。
| - | 预测是猫 | 预测是狗 |
|---|---|---|
| 实际为猫 | 98 | 2 |
| 实际为狗 | 15 | 85 |
这个表格还有一个学名叫做“混淆矩阵”(confusion matrix)。矩阵的行与列分别代表了测试所使用的真实样本分布以及模型的预测结果。对于基建维护小队来说,为了保证电力管道等设施的正常运行,他们格外关注幽灵猫的检测结果,所以张小白在测试中将幽灵猫认定为阳性样本。本次测试中模型给出的98个正确猫样本又被称为真阳性结果。而他之前计算的“准确率”实际上是真阳性样本占全部阳性样本的比例,学名叫作“真阳性率”。它还有一个别名“召回”。对于维护小队来说,他们在执行任务时希望能尽可能的找出隐藏在电站中的全部幽灵猫,所以召回越高越好。
与幽灵猫相对应,幽灵狗在这个二元分类任务中自然被认定为阴性样本。考虑到幽灵狗在某种程度上可以驱赶误入电站的火星生物,保障电站安全运行,维护小队希望执行任务过程中不要误伤到幽灵狗。所以,被误判为阳性(幽灵猫)的幽灵狗,有一个学名叫作假阳性结果。假阳性结果占全部阴性样本的比例,称作假阳性率,或者误报率。显然,对于维护小队来说,这个值越低,被误捉的幽灵狗越少。而张小白之前的测试中正是缺失了这个指标,导致测试结果不完整。
至于准确率(Accuracy),则有专门的定义:
$$准确率=\frac{正确分类的照片数量}{照片总数}=\frac{98+85}{100+100}=91.5\%$$
这个数值与之前的98%相比差了不少,这是由于当前分类器对幽灵狗的判断失误过多,拉低了整体水准。但是,此时的准确率才是模型真正的准确率。
“有什么办法能降低误报率吗?毕竟,被误捉的幽灵狗最后还需要遣送回电站去,这来来回回都是成本。”
“当然可以了,只要提高阈值就可以降低误报。”张小白自信地回答,“模型的输出为一个范围0~1的小数,这个数字越接近1,代表模型预测结果为猫的可能性越大;反过来,这个数字越接近0,代表模型预测结果为狗的可能性越大。例如这张误报为猫的照片,模型预测结果为0.6。我只要把阈值设定为0.7,那么它的预测结果就是狗了。”
“可是,这张猫片的预测结果也是0.6。这么一来,正确分类的猫片数量岂不是要下降,召回、误报、准确率也会发生变化。”
“是的。”
“这样的话,如果我有两个模型,该如何比较他们的优劣?不的模型的阈值特性不同,使用相同的阈值来比较很明显是不合适的。而且如果阈值设定不合理,模型的准确率会大幅下降,也许会出现优秀模型的指标反而较差的现象。”
“是的。所以,更加全面的比较,需要更加科学的方法。”
一个模型,两条曲线
首先,阈值虽然是可变的,但是变化范围是有边界的,超过模型输出范围的阈值将会失去意义。所以,我们可以通过枚举阈值来获得模型指标的全部可能值。当然,这些指标也和阈值一样,不再是一个数,而是一组数。此时,比较两组数的最好方式是将它们绘制成曲线。
ROC曲线
例如测试时计算过的召回与误报率,这些指标本身的范围位于0与1之间。假设我们把阈值从0-1没隔0.01扫描一遍,最终会得到100个召回数据与100个误报率数据。如果以误报率为横轴,召回为纵轴,便可获得一条曲线。如果有两个模型,它们的曲线可以绘制在同一幅图中。
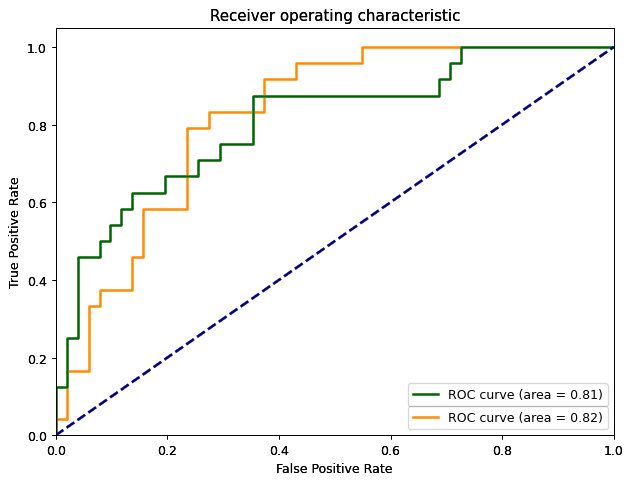
这条曲线有个专有名称叫作“受试者操作特性曲线”(Receiver operating characteristic curve),简称ROC曲线。它可以用来比较不同阈值特性模型的好坏。模型左上角(0, 1)意味着误报率为0,召回为1。当然,这在实际情况中几乎是不可能的,优秀模型的ROC曲线会尽可能的靠近这个点。这张图还可以方便的比较特定指标下模型的优劣。例如当召回为0.9时,橙色曲线对应误报率为0.4;而绿色曲线的误报率为0.7。如果维护小队选择的话,大概率会选择误报率小的那一款模型。
PR曲线
与ROC曲线类似,还有一种常用的曲线叫作精确率-召回曲线(Precision-Recall)。这里的精确率(Precision)定义为:
$$精确率=\frac{正确分类为阳性样本的数量}{预测为阳性样本的全部数量}=\frac{98}{98+15}=86.7\%$$
从定义不难看出,精确率反映了模型预测出的全部阳性样本中,正确的比例有多高。这个数值同样受阈值影响。因此可以像ROC曲线一样绘制出精确率-召回曲线。
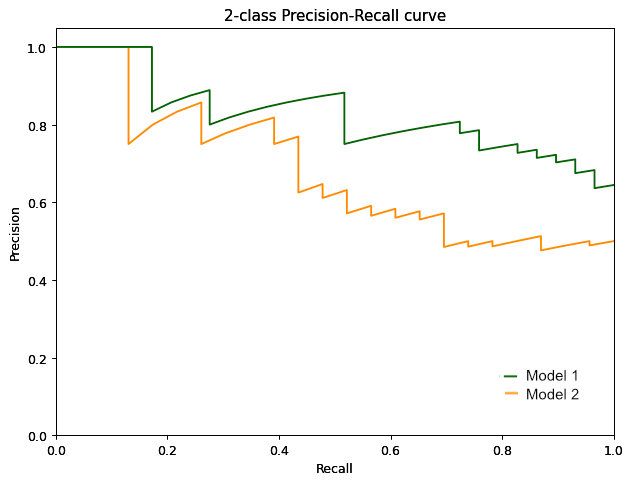
与ROC曲线不同的是,PR曲线中的理想位置为右上角(1, 0),它代表模型不但找出了全部阳性样本,而且预测出的阳性样本中没有一例误报。当然,这是理想情况。实际中模型的PR曲线会去尽可能的贴近这一点。同样,两个模型想比较时可以观察下哪个模型更加贴近右上角。例如上图中,模型1的表现要明显优于模型2。
“原来如此,”同事赞叹到,“你这火星大学果然没有白上!”
“那必须的!我做毕业设计的时候还养过一只幽灵猫呢!”
“真的?现在还在吗?能让我撸一把吗?”同事睁大了眼睛。
“你猜!”



评论 ()