
执迷于架构创新?训练与缩放策略能让老ResNet焕发新生。
ResNet是由何凯明等人在2015年提出的一种深度神经网络架构。它通过跳跃连接改善了深层网络在训练时遇到的梯度消失问题,成为深度神经网络的典型架构。在这篇题为 Revisiting ResNets: Improved Training and Scaling Strategies 的文章中,作者Irwan Bello等人认为,即便是老架构ResNet,在改进的训练与缩放策略下,也能获得与最新架构EfficientNet接近的性能。并提出在搜寻最佳模型时的可行方法。你可以在这里找到原文:
以下为我的读书笔记。
依托深度神经网络灵活的机构,在模型架构上做文章是一项非常受欢迎的决策。但是,大多数研究提到的模型架构创新往往合并了全新的训练方法,而用来作对比的基线模型却是采用老方法训练的。所以,架构创新带来的收益究竟有多高?
自AlexNet发布以后,深度神经网络的改进方向可以归纳为四点:模型架构、训练与正则化方法、缩放策略、额外的训练数据。
模型架构方面,从早先的手工设计架构到最近的自动架构搜索,以及引入注意力机制或者特殊的lambda层。正则化方面,dropout、label smoothing、stochastic depth、dropblock,data augmentation有效的提升了模型泛化能力。改进的学习率计划提升了最终的准确率。规模缩放是另一个维度,并可以分解为深度、宽度与分辨率三部分。ResNet18~200在深度上缩放;MobileNet在宽度上缩放;EfficientNet则在三个方向上一起缩放。额外的训练数据,无论是标记的、弱标记的亦或是无标记的,都可以用来改善结果。
训练与正则化改进
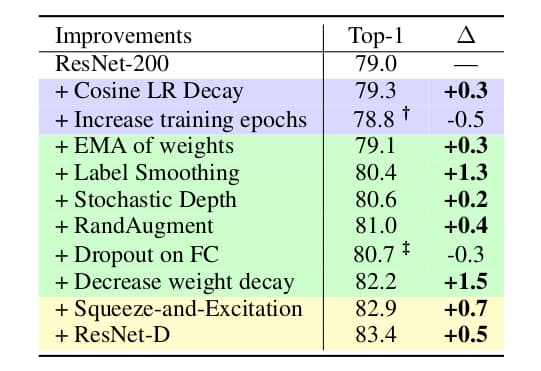
作者采用ResNet-200作为实验模型开展了递增式研究。比对基础模型首先训练90个epoch。之后采用Cosine LR Decay带来0.3个点的准确率提升。如果继续训练到350个epoch,由于过拟合造成准确率下降0.5个点。而加入正则化RandAugment、Stochastic Depth与label smoothing有利于精度提升,+1.8个点。继续加入dropout则会造成负面影响,下降0.3个点。此时需要降低weight decay的参数值,+1.5个点。然后再通过轻度改变模型架构,使用Squeeze-and-Excitation与ResNet-D,最终将模型准确率从79.0%提升至83.4%。
缩放改进
作者全面测试了以下缩放规格:宽度乘数[0.25,0.5,1.0,1.5,2.0],深度[26,50,101,200,300,350,400],分辨率[128,160,224,320,448]。训练周期数同为350个epoch。作者发现,最佳的缩放策略取决于训练区间。并提出:缩放策略1:在过拟合发生的区间,采用深度缩放。对于长周期训练,缩放深度优于缩放宽度。对于短周期训练,缩放宽度优于缩放深度。缩放策略2:缓慢提升分辨率。简单的说,EfficientNet b7那样的分辨率太大了。
作者还提出两个缩放陷阱。第一,仅依靠小模型或者小训练epoch推导缩放策略。这些策略对于大模型长训练周期可能不适用。第二,在单个次优初始架构上推导缩放策略。这可能导致后续缩放策略失效。
为此作者提出的缩放策略为:对新任务,应当选择多个尺度的模型并跑满训练周期,以决定哪个尺度是最佳的。同时作者认为,像EfficientNet那样不考虑模型规模而独立缩放深度、宽度与分辨率是次优的。
数据改进
作者采用改进后的ResNet-RS,并额外使用了130M伪标签图像,成功的提升了准确率到86.2%。
如何看待架构改进
经过这些改进之后,老ResNet也能获得最新模型如EfficientNet几乎等同的性能,而且速度更快。因此作者认为:架构改进固然有效,但是同时会造成复杂度上升与速度降低,其收益可能不如放大更简单模型的规模更明显。例如GPU上depthwise卷积就不如传统卷积跑得更快。
如何找到最佳模型
作者推荐开始时从简单高效的模型入手,并采用多个不同规模的模型以获得性能曲线。
总结
作者的态度往往在读完文章后才能感知。本文作者毫无疑问对一股脑扎堆架构创新的做法提出了质疑,并且使用经典架构ResNet与大量的实验数据证明了自己的观点。文章对于模型性能分析的部分与ShuffleNet异曲同工,值得我们在实际模型选型时参考。
微信扫一扫分享



评论 ()