TensorFlow 2有哪些坑
Numpy瑟瑟发抖

封面图片:修改自nyankichi5656
为了更加高效的从TF1迁移到TF2,最近在使用TensorFlow 2复现HRNet面部特征点检测项目,踩了不少坑,记在这里以便回顾。
以下内容完全是我的主观感受,实际情况需要读者自己辨别。
无法保存子类化Keras模型
TensorFlow 2力推Keras。相信这是因为高阶API Keras可以降低使用门槛,这样做符合“An end-to-end open source machine learning platform for everyone.”的愿景。但是高阶API也有副作用。例如HRNet的融合阶段网络结构异常复杂,需要使用subclass的方式来自定义layer。最开始我按照官方指南仅仅实现__init__与__call__函数,网络可以正常执行,但使用keras来保存模型会报错。一番研究后才知道自定义layer还必须实现get_config函数,模型才能被keras保存与加载。
TensorBoard无法显示Graph
这是非常让人费解的一个issue,log中不再包含可视化的运行图。官方只是在页面丢下了一个未解决#issue 1961的地址。没有可视化的运行图,debug网络结构将更加困难。
 tensorflow
tensorflow
略鸡肋的数据API
TensorFlow强烈推荐使用tf.data API来加速数据IO。它的表现也的确很棒,前提是你的数据预处理都是常规操作。HRNet使用了随机旋转、缩放以及翻转作为数据增强手段。对于图像来说这些都是常规操作,但是对于特征点检测来说,这些操作要同步到mark点上。TensorFlow的tf.image模块仅仅提供了有限的操作,所以我不得不借助OpenCV与Numpy实现了图像与mark点的同步。但是这些增强函数与tf.data API出现了兼容问题。
最开始我使用TFRecord文件作为数据源。此时增强函数放在 dataset.map()函数中会报错——增强函数需要处理的对象类型必须是Tensor,而非OpenCV中的mat。
这个问题官方在Guide中“Applying arbitrary Python logic”章节有提到过,并推荐使用tf.py_function来解决这个问题。但是我在使用py_function时出现了无法将浮点数转换为Tensor的错误。
于是改换第三种方案,将训练数据与增强函数打包为generator,然后使用 from_generator 来构建数据源。但是这种方式也出错了,错误的原因是pathlib提取出的string字段在验证是否在一个list中存在时,byte 类别与 str 类别无法兼容。这段代码在非TensorFlow环境下没有任何问题。也许TensorFlow处理string时有着他自己的逻辑。
于是改换第四种方案,使用 keras.util.Sequence。好消息是这种方式没有出错,但是坏消息是,使用这种方式构建的数据集在fit()函数调用时没有任何反应。像极了第一次使用TF1时的queue_runner。
深度学习框架之间也存在着激烈的竞争。TensorFlow之前经常被诟病的地方在于上手难度高,这也是TF2将eager excution作为默认模式,以及力推Keras API的原因。但是TensorFlow的野心不止于此。针对web的TensorFlow.js,针对移动端与微控制器的TFLite,针对生产环境的TFX,甚至还有对Swift语言的支持。TensorFlow给自己的定位不仅仅是深度学习框架,而是在构建以深度学习为核心的生态系统。
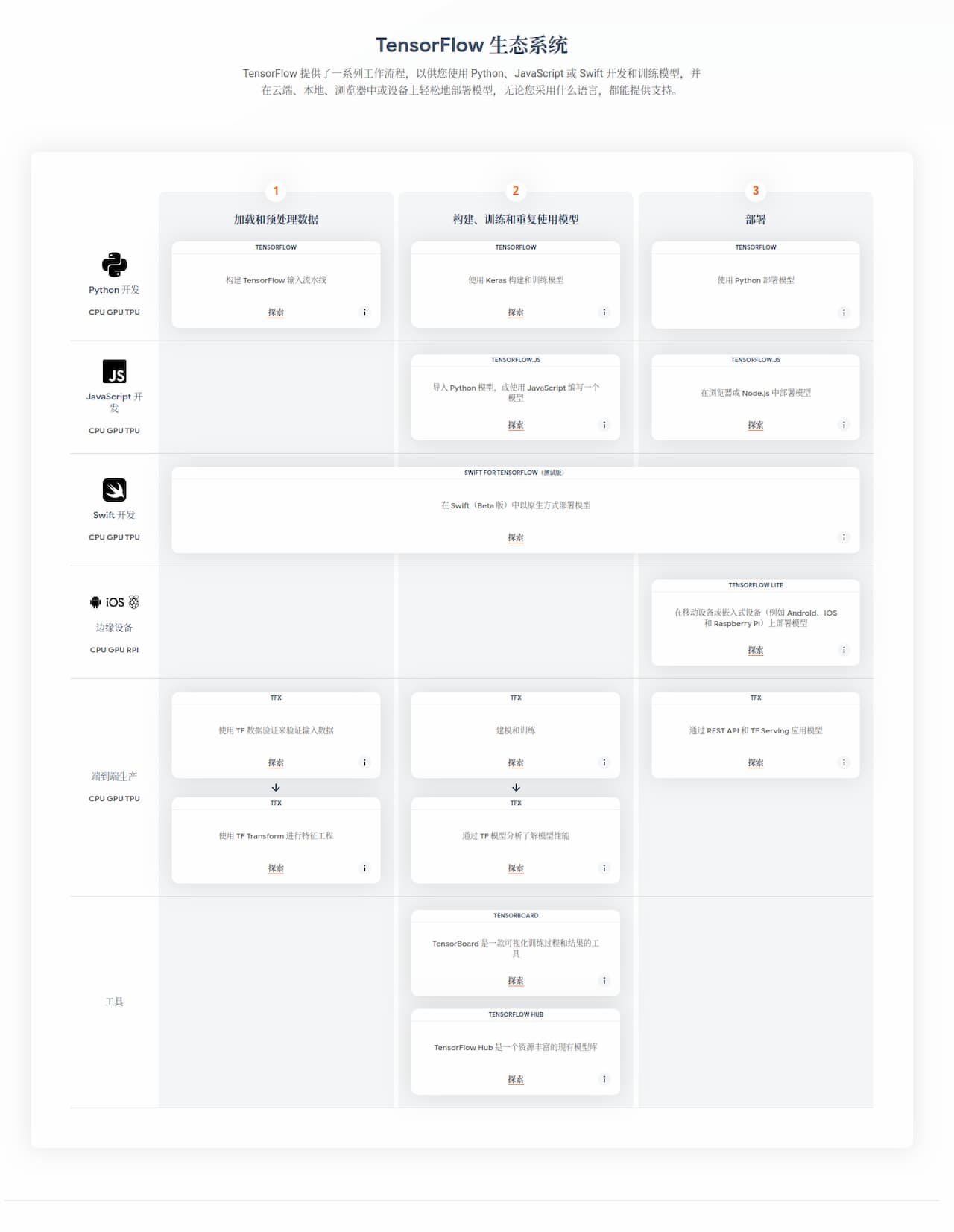
要构建生态系统,底子必须得广而坚实。这直接导致TensorFlow摊子铺的越来越大、要覆盖的内容越来越多。这对开发者来说不一定是好事。表面上有了更多的选项,例如构建模型时有高阶API keras,也有tf.module可以随意发挥。但是实际上,什么都想做可能会造成什么都做不好。急于构建完整的生态会对现有的第三方库形成天然的排斥。不信你看,TensorFlow现在都提供Numpy API了呢!


Comments ()