
如何在微信中与ChatGPT聊天。
我花了大概一个月的时间,成功实现了ChatGPT的微信接入。
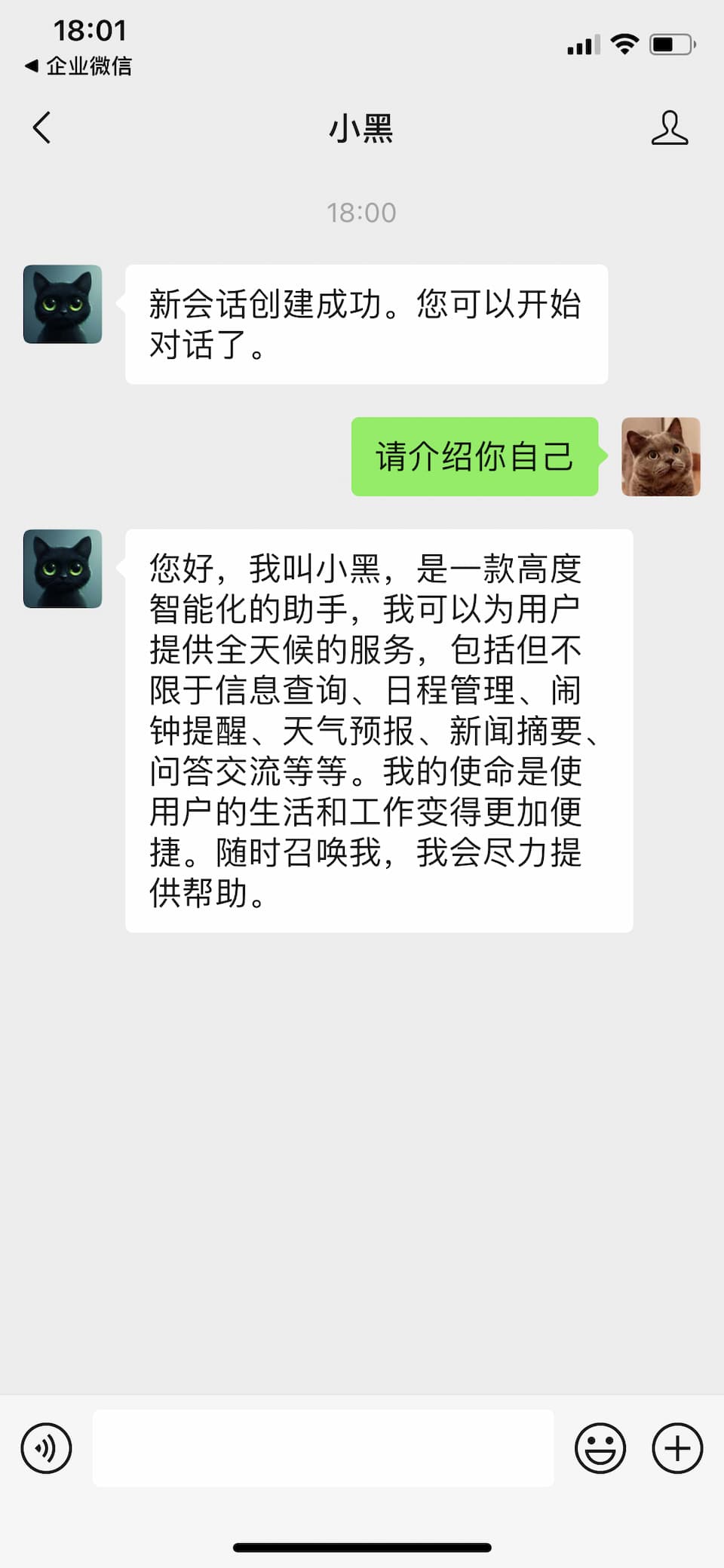
这是我为了学习Rust语言而做的个人项目。无需复杂的操作,在微信里与目前世界上最昂贵先进的人工智能对话。
受益于Rust这门语言,服务本体为一个独立的二进制文件。经过打包后的deb安装包为3.5MB大小,安装后简单配置下即可使用。同时支持GPT3.5与GPT4。在最便宜的2核2G云服务器上可以流畅运行。
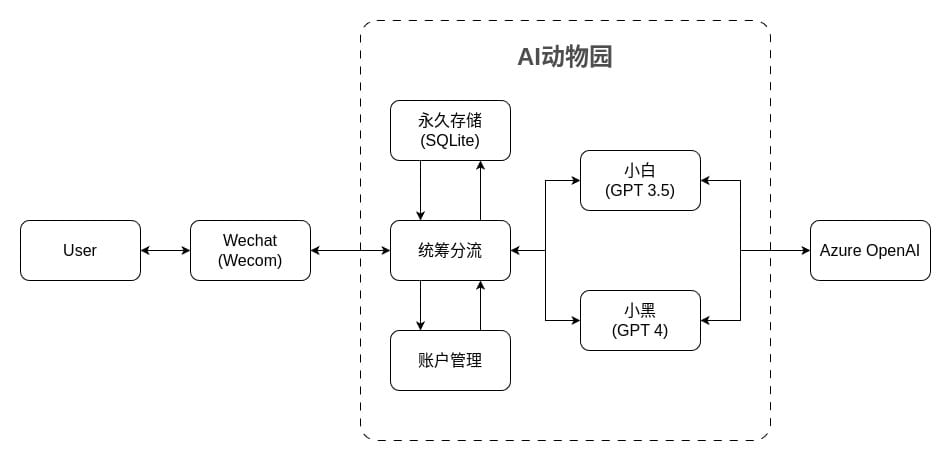
这套服务的架构图大致如下:
需要解决的外部问题
要在微信里接入ChatGPT有两个显而易见的难题。第一是稳定的GPT模型来源;第二是可靠的微信接入。这两者目前没有完美的解决方案,需要曲线救国。
第一个问题的解决方法是避开OpenAI,转向微软云服务Azure OpenAI。这是Azure面向企业提供的付费OpenAI模型调用服务。基本上覆盖了全部OpenAI模型。面向企业的付费服务、再加上微软云作为靠山,算是一个相对稳妥的解决方案。具体的费用可以参考上一篇文章“Azure OpenAI的定价与使用前提”。
第二个问题,直接接入微信聊天难度非常高,微信小程序开发已经严重偏离了我的主要目标。企业微信应用可以与用户直接对话,而且用户加入企业微信后即可借助企业微信的插件实现微信内与AI对话。
需要实现的具体功能
上下游的接入问题有了初步方案后,接下来就是具体的服务实现。这一版方案我起了一个名字叫“AI动物园”。用户加入企业后就像进了动物园一样,可以与不同的AI对话。AI动物园需要实现以下主要功能。
与企业微信服务器通讯
这里我采用了axum来响应微信服务器发送来的http请求。Axum是一款使用Rust语言开发的web应用框架,它的开发者同时开发了tokio这款Rust下非常流行的异步运行时。除了响应服务器请求,还需要主动向服务器发送请求。这里我采用了reqwest。Reqwest的易用性可以极大地节省开发时间。这两个库均支持异步运行时。
与Azure OpenAI服务器通讯
OpenAI提供了部分语言的官方SDK,如Python。GitHub上也可以找到诸多开源项目可以引用。但是我研究了一下Azure官方文档,发现我的使用场景比较简单,使用REST API就能实现。所以这里同样使用了reqwest来封装具体的模型调用过程。
统筹分流
用户消息是多样的,因此一个重要的功能是消息的分拣。动物园同时支持GPT3.5与GPT4两种模型,具体的实现上体现为两款不同的企业微信应用。用户消息一次只能发送给一个应用,需要提前分拣。从性质上看,消息还可以分为指令消息与对话消息两种。像余额查询、消耗查询、会话管理等属于指令消息;其它需要AI来响应的内容则为对话消息。指令消息与对话消息在动物园是由不同的模块实体来处理的,也需要按需分拣。
账户管理
服务支持多用户。凡是在企业内的用户,且在企业微信内赋予足够权限的前提下,都可以使用该服务与AI对话。因此,服务内部存在一个与企业微信账户一一对应的账户。另外AI的调用是付费服务,因此需要有把每条对话所消耗的资源与账户金额关联,并且在超出账户限额时仅响应指令消息。这些都是账户管理的功能。
永久存储
无论是用户账户还是会话消息,都需要以某种形式存储下来。尤其是会话消息,收到的用户消息不能直接发送给AI,需要在本地拼接成AI可以处理的会话记录,才可以发送。考虑到使用者数量、单次请求内容的容量以及请求频率,使用成熟的SQLite这种嵌入式数据库是一个比较稳妥的选择。
会话响应
响应用户消息是这套服务的核心功能。这部分抽象为独立的助手模块以支持多个不同的AI角色同时处理用户消息。同时,有较大差异的部分例如会话格式、存储、后端API调用等,作为内部实现都封装在这里。不同助手需要实现动物园的一个公共trait,以便统筹它们的功能。助手无权管理用户账户。所有的账户操作由统筹分流与账户管理模块执行。
实现了上面这些功能,在微信中与ChatGPT对话应该就没啥问题了。不过这里还有些具体的细节需要注意。
腾讯的加解密算法
官方没有提供Rust可用的加解密库,需要自行实现。我在实现时发现这部分加解密内容“非标准”,需要在现有的Rust加解密库基础上严格按照文档调整后才可使用。具体体现为BASE64编解码方式、以及加密字节的补位操作。我把这部分内容开源在GitHub并发布在了crates.io,你可以直接使用。
 wandering-ai
wandering-aiOpenAI的消息长度限制
每一个GPT模型都有自己的Token长度限制,例如GPT 3.5 turbo的长度限制为4096。随着用户与AI会话的长度增加,超过限制长度只是时间问题。一旦会话超长,AI的API调用会返回400错误。此时有两种处理办法。一是开启全新会话,丢弃之前全部消息内容。二是丢弃部分会话内容,仅保留最近的若干消息。
AI动物园现在支持这两种方式。第一种方式需要用户手动触发,避免粗暴丢弃会话影响用户使用。第二种则是服务的默认行为,这样用户可以体验到无中断的持续会话。而在具体的会话长度判断上,几经周折后选择了引入token编码器来实现。虽然OpenAI的API会返回每一条消息消耗的prompt token与completion token数量,但是使用这些参数推算每条消息的token需要另外跟踪每次会话的起止点,大大增加了服务复杂度。OpenAI推荐使用tiktoken来实现token编码,Rust社区有与之对应的绑定包tiktoken-rs可用。这个包会导致最终的安装文件体积增大约1MB,但是综合考虑是值得的。
数据库选型
这种轻量级的应用,其数据库规格自然需要与之对应。Redis、MongoDB这类数据库显得有些大材小用,而且引入了额外的部署操作。SQLite这种轻量的嵌入式数据库看起来是不错的选择。但是在具体的使用过程中我发现传统的关系型数据库在使用时不够“Rust”。我之前从未使用过SQL数据库,因此花了不少时间学习了一下SQL语言,数据库ORM等概念,最后选择了Diesel这个库作为数据库交互的中间桥梁。借助Diesle,可以将一些数据库的操作封装在最终编译好的可执行文件内部,实现单文件交付。同时Diesel也可以在某种程度下简化rust对数据库的操作。
但是,SQLite毕竟老了。即便在Diesel的帮助下,仍然无法避免SQL语言的书写;一些简化的操作是以额外冗余的Rust数据结构为代价;Diesel指令也是开发时不可缺少的操作。可以预见采用SQLite必定会拉低后续功能开发的效率。在数据库选型过程中我发现SurrealDB是一个不错的选择。原生支持Rust数据结构,支持嵌入式数据库。当然也有其它一些非常现代化的数据库值得关注,按需选择。
以上几点是我在开发过程中踩坑的地方,并且花了一些时间来解决。列在这里希望能有所帮助。
这里推荐一些我认为比价好用的技巧或者库,它们可以有效解决开发过程中一些繁琐问题,提升开发幸福感。
在二进制文件中嵌入版本信息
在C/C++项目中,需要通过额外定义一个 config.in 文件然后借助cmake来实现版本号的嵌入。在Rust项目中,版本信息早已在Cargo.toml文件中存在。在代码中使用版本号仅需一行代码:
const VERSION: &str = env!("CARGO_PKG_VERSION");
CARGO_PKG_VERSION 这个环境变量即为编译时的版本号。
打包deb安装文件
单一二进制文件交付听起来很酷,用起来也很方便,但是要在实际场景中生存下来,还需要一些辅助文件例如自身配置文件、Systemd unit文件;在安装或者卸载时还需要一些额外操作例如创建或者删除目录、更改文件权限等等。这些额外的操作往往需要在操作系统层面来实施,而cargo-deb这个工具就是为这个目的而生。它可以自动从Cargo.toml中读取必要信息,打包deb安装包,并按照你的指示生成系统服务安装、终止、移除时需要使用的脚本文件。使用起来非常方便。如果你对这部分内容感兴趣,可以阅读我之前写的文章“在Rust项目中打包deb安装包”。
 yinguobing
yinguobing
使用Toml配置文件
ini、xml、json、yaml等都是常见的配置文件格式。但是在Rust中,首选的配置文件格式应当是Toml。这也是Cargo自己的默认配置文件格式。Toml对人类非常友好,易于阅读,易于书写。借助serde,在Rust中可以直接将结构体与配置文件中的内容绑定,没有多余的参数类型格式检查与转换。例如AI动物园的配置文件中规定了助手的配置:
# 会话助手。agent_id唯一。需要指定关联provider ID,二者为一对一关系。
[[assistants]]
agent_id = 1000002
name = "小白"
token = "XIAOBAI_TOKEN" # 环境变量名
key = "XIAOBAI_KEY" # 环境变量名
secret = "XIAOBAI_SECRET" # 环境变量名
prompt = "你叫小白,是一位友善的智能助手,热衷于为人类用户提供有价值的信息。"
provider_id = 1
context_tokens_reservation = 1024 # 当会话超长时,移除早先会话直到空间满足本项要求对应到Rust代码中定义如下:
/// 智能助手初始化所需要的参数
#[derive(Deserialize, Clone)]
pub struct Config {
pub agent_id: u64,
pub name: String,
pub token: String,
pub key: String,
pub secret: String,
pub prompt: String,
pub provider_id: u64,
pub context_tokens_reservation: u64,
}从文件中读取配置仅需如下代码:
let config_txt = match std::fs::read_to_string("config.toml") {
Err(e) => panic!("无法读取配置文件。{e}"),
Ok(c) => c,
};
let config: Config = match toml::from_str(&config_txt) {
Err(e) => panic!("读取配置文件出错。{e}"),
Ok(c) => c,
};非常简洁。
以上内容为我这段时间使用Rust开发项目涉及到的重点内容总结。除此之外还有一些比较琐碎的内容这里不再列出,以后有机会的话另外成文。基本功能开发完成后我在微信朋友圈小范围征集了第一批试用者,有朋友反馈还不错!
最后放一个代码统计。
Date : 2024-03-25 18:43:54
Directory /home/robin/Developer/wecom-gpt-workspace
Total : 35 files, 5606 codes, 482 comments, 694 blanks, all 6782 lines
| language | files | code | comment | blank | total |
|---|---|---|---|---|---|
| TOML | 9 | 3,205 | 12 | 382 | 3,599 |
| Rust | 18 | 2,241 | 461 | 288 | 2,990 |
| Markdown | 4 | 91 | 0 | 12 | 103 |
| SQL | 2 | 35 | 9 | 0 | 44 |
| YAML | 2 | 34 | 0 | 12 | 46 |


Comments ()